L’IA ha cambiato il modo in cui costruisco software
È un po’ che non scrivo più la maggior parte del codice a mano. Descrivo ciò che voglio, rivedo, correggo la rotta, e l’IA esegue. Questo ha cambiato tutto: ciò che prima richiedeva un pomeriggio di digitazione oggi esce in pochi minuti. La consegna ha smesso di essere una questione di quante ore riesco a stare seduto ed è diventata una questione di quanto bene riesco a guidare la macchina.
Ma ogni guadagno di velocità mette in luce un nuovo collo di bottiglia. E il mio è apparso in fretta.
Il collo di bottiglia che è comparso al suo posto
Un agente di codice non ha memoria tra una sessione e l’altra. Quando chiudo il terminale e lo riapro domani, non ha la minima idea di cosa avevamo deciso ieri, perché l’avevamo deciso, cosa era già pronto e cosa mancava. Ogni sessione comincia da zero.
Finché il lavoro era piccolo, riuscivo a tenerlo a mente. Ma quando l’IA ha cominciato a consegnare davvero in fretta, mi sono ritrovato con diversi fronti aperti allo stesso tempo — e la parte più difficile della mia giornata non era più scrivere codice. Era ricordare lo stato delle cose. Cosa era deciso, cosa dipendeva da cosa, cosa era già stato fatto e cosa era rimasto a metà.
In altre parole: la documentazione ha smesso di essere un lusso “da fare poi” ed è diventata ciò che tiene in piedi il progetto. Senza, l’IA delira — riscrive ciò che già esisteva, ignora una decisione che avevamo preso la settimana scorsa, esegue nell’ordine sbagliato. La qualità di ciò che consegna ha iniziato a dipendere direttamente da quanto bene il lavoro è organizzato e registrato.
Ho provato quasi tutto — e tutti sbattevano contro lo stesso muro
Non mi sono messo subito a reinventare la ruota. Ho passato mesi a testare i plugin e le skill che la community stava creando proprio per risolvere questo: il superpowers, il GSD (get-shit-done), il cavekit, tra gli altri.
Hanno tutti i loro meriti. Sono progetti ben pensati, pieni di buone idee su come dare processo e disciplina a un agente. Ho imparato parecchio da ognuno. Ma, alla fine, tutti sbattevano contro lo stesso problema di fondo: il modo di conservare ciò che l’IA “sa” era un mucchio di file di spec in Markdown committati nel repository.
E questo, in pratica, fa male in due modi:
- Inquina il git. Ogni pianificazione diventa una manciata di
.mdche salgono insieme al codice. La cronologia si riempie di rumore di processo, e il repository si porta dietro uno strato di scartoffie che non è, di fatto, il prodotto. - Si disallinea in fretta. Una spec è la foto di un momento. Il giorno dopo la realtà è già cambiata, ma il file resta lì, ad affermare con sicurezza cose che non valgono più. Così l’IA legge un piano vecchio come se fosse verità e il delirio non fa che peggiorare.
Volevo l’opposto di un file statico: volevo uno stato vivo, che l’IA consultasse e aggiornasse man mano che il lavoro avanza — e non l’ennesimo documento che invecchia da solo in un angolo del repo.
E se la board fosse della stessa IA?
È lì che mi è venuta l’idea. Ogni team di software ha già risolto il problema del “cosa fare, perché e in che ordine” — si chiama bacheca delle attività. Jira, Trello, Linear. Perché l’IA non dovrebbe avere la sua?
Solo che con un’inversione importante: questa board sarebbe stata usata prevalentemente dalla stessa IA, via MCP (il protocollo che permette all’agente di consultare e modificare strumenti esterni). L’agente legge lo sprint attivo, prende il prossimo card, registra le decisioni, allega il commit, chiude l’attività. E io — l’essere umano — entro dall’interfaccia soprattutto per seguire e revisionare: vedere cosa si sta facendo in tempo reale, trascinare i card, lasciare un commento che lui legge nella sessione successiva.
Non è l’IA che usa uno strumento per umani. È uno strumento progettato per l’IA, con una finestra da cui l’umano può guardare dentro.
È così che è nato claude-organizer
claude-organizer è ciò che è uscito da questa idea. Non è solo una board: è un ecosistema attorno all’organizzazione del lavoro dell’agente. Ha progetti, sprint, storie e sotto-attività, blocker, tag, priorità — e un’interfaccia in Nuxt che rispecchia tutto questo in tempo reale, con aggiornamento via WebSocket mentre l’IA lavora.
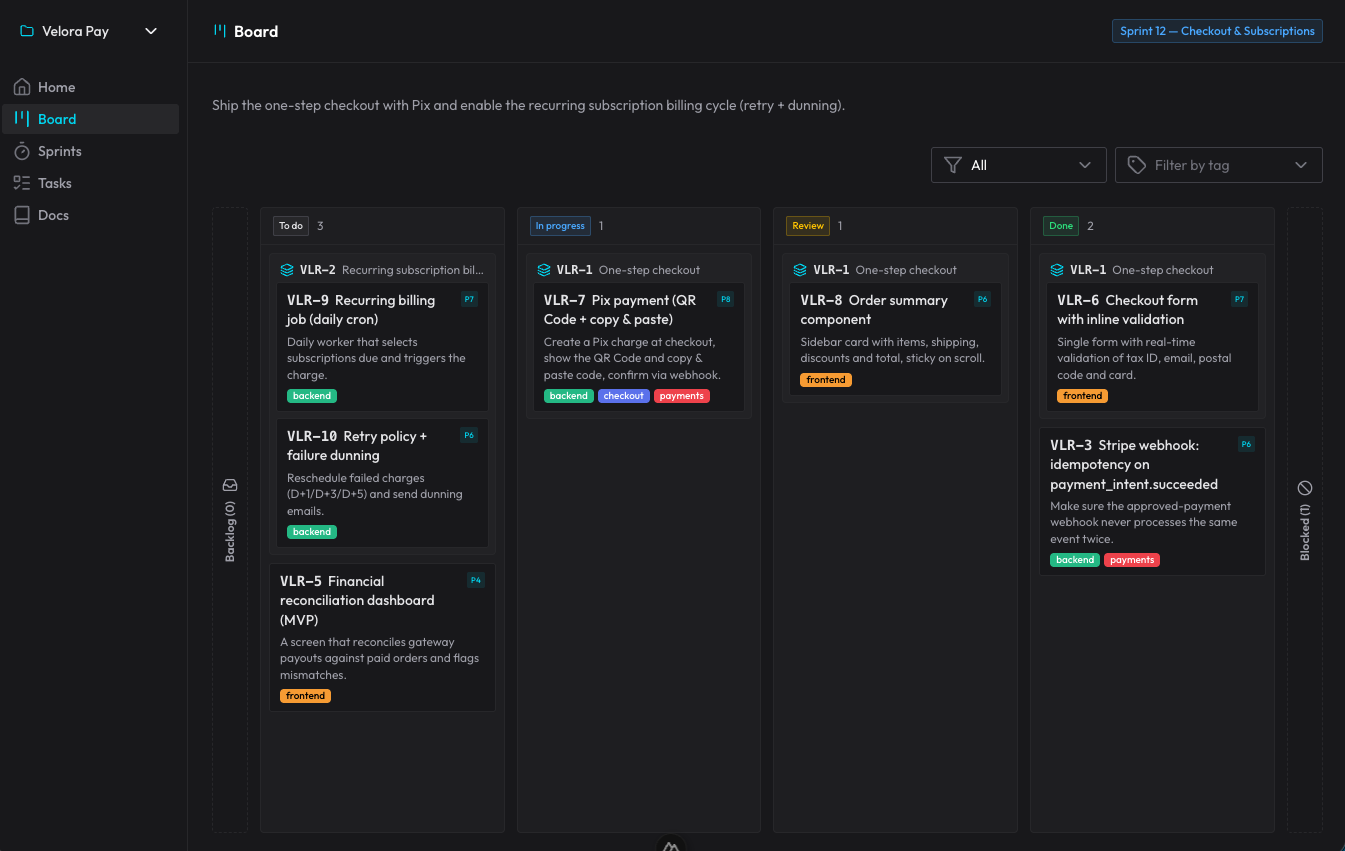
L’intero flusso avviene tramite skill + MCP. Sono cinque skill che si attivano in base a ciò che dico, senza che io ne chiami nessuna a mano: una per orientare e gestire la board, una per pianificare una nuova richiesta in sprint/storie/attività, una per eseguire un card lungo il suo ciclo di vita, una di review (un gate obbligatorio, eseguito da un subagente pulito, che verifica i criteri di accettazione e dà la caccia ai bug), e una di autopilot per avanzare da sola attraverso diversi card pronti. La documentazione durevole — architettura, decisioni (ADR), pattern — vive nei docs dello stesso organizer, che l’IA legge prima di reinventare.
Come funziona nella pratica
La svolta, per me, è stata questa: dato che ciò che è stato pianificato vive nell’organizer e non nella sessione, posso eseguire ogni attività in una sessione completamente pulita, senza perdere qualità. L’agente apre, legge la board, capisce dove si trova, fa il lavoro. Non importa se il contesto precedente è già evaporato — il piano non era nella sua testa, era nel database.
Questo risolve in un colpo solo i due fantasmi: l’ordine di esecuzione (cosa dipende da cosa è esplicito nei blocker) e il delirio (parte da ciò che è stato deciso, non da un ricordo vago). E mi permette di portare avanti diversi fronti allo stesso tempo, in sequenza o in parallelo, senza perdermi.
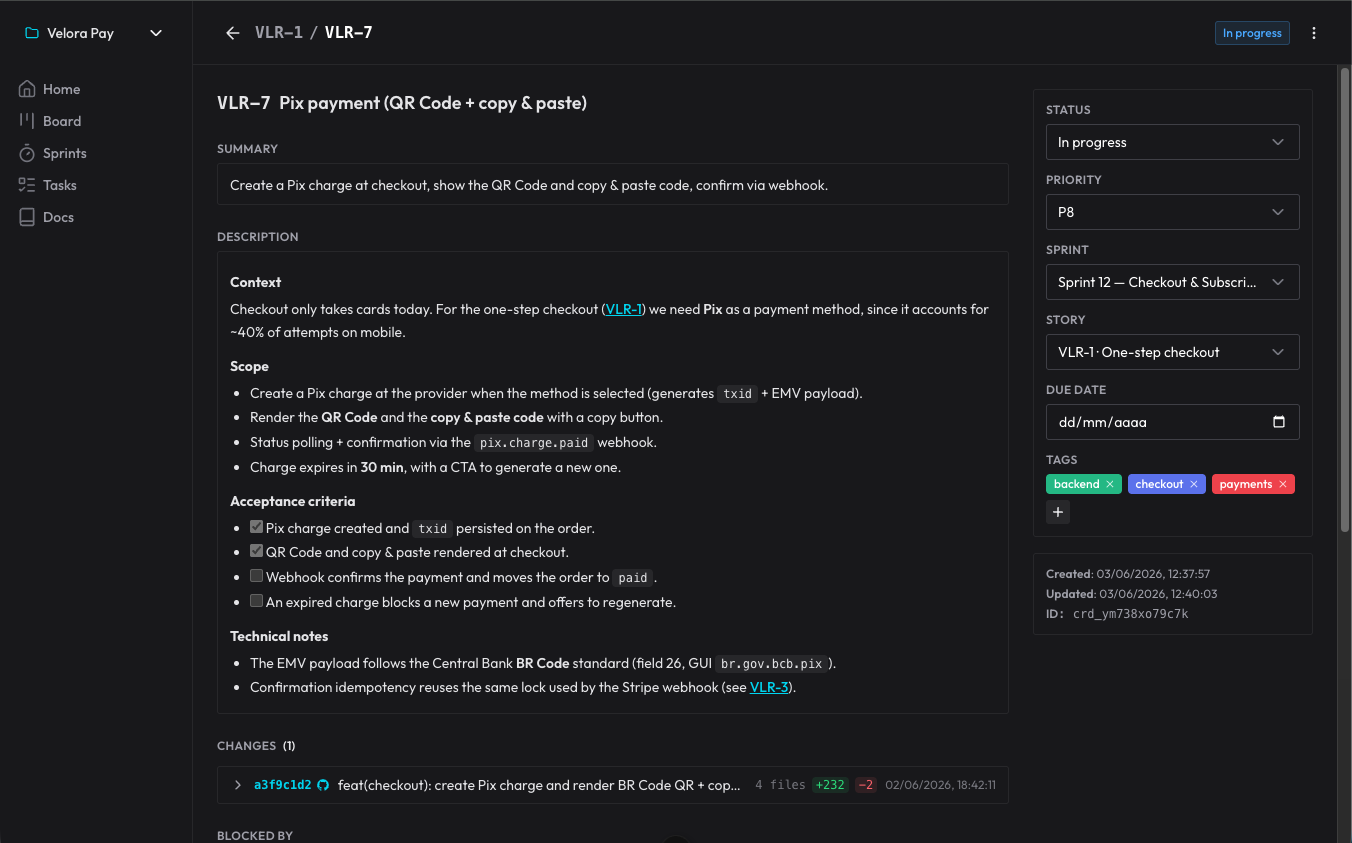
Le decisioni non si perdono perché diventano commenti sul card: l’agente registra il perché ha fatto in un certo modo, e io rispondo lì. Nella sessione successiva, legge i commenti che non aveva ancora visto e prosegue da quel punto. È un registro di decisioni che sopravvive alla fine di ogni conversazione.
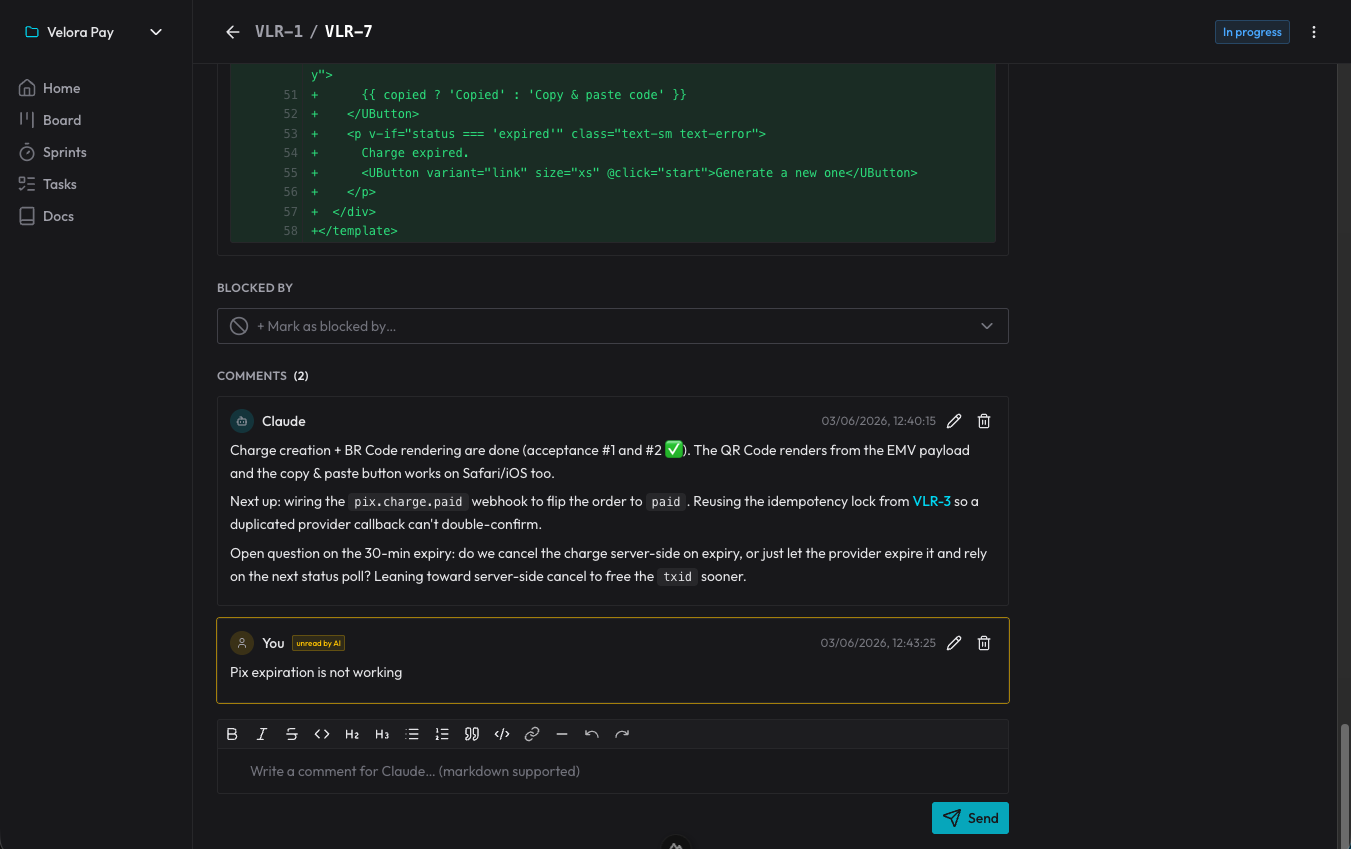
L’effetto collaterale più piacevole: il repository è tornato a essere solo il prodotto. Niente cartelle di spec che ingrassano il git. Il “cosa fare e perché” abita nell’organizer, accessibile da qualsiasi sessione; il codice abita nel repo. Ogni cosa al suo posto.
Come iniziare
Gira come plugin di Claude Code (le cinque skill + il server MCP), con l’intero stack in Docker. Per avviarlo:
1. Avvia lo stack (Postgres + migrations + API + UI + MCP, in un colpo solo):
git clone https://github.com/fmilioni/claude-organizer.git
cd claude-organizer
cp .env.example .env
docker compose up -d --buildLa UI sta su http://localhost:4401, l’API su :4400 e l’MCP su :4402/mcp. Le migrations girano da sole prima che l’API si avvii.
2. Installa il plugin — consegna le skill e registra l’MCP, senza bisogno di claude mcp add:
/plugin marketplace add fmilioni/claude-organizer
/plugin install claude-organizer@claude-organizer3. Parla con Claude. Basta parlare. “Voglio pianificare questa funzionalità” attiva la skill di pianificazione; “andiamo avanti, qual è il prossimo?” fa leggere la board all’IA e proseguire da dove si era fermata. Le skill si attivano in base a ciò che dici — non devi memorizzare nessun comando.
Il progetto è open source (MIT). Si può far girare al 100% in locale con Docker oppure ospitarlo su una VPS e puntarci Claude Code.
Voglio sapere come lo organizzi tu
Questa è, in fondo, la ponte che mi interessa di più: portare la disciplina di processo che l’ingegneria ha già dentro al nuovo modo di costruire, con l’IA al volante. claude-organizer è il mio tentativo di colmare questo buco — ed è nato da un dolore reale, dal vedere del buon lavoro perdersi tra una sessione e l’altra.
E tu, come stai gestendo questa cosa? Butti tutto in un file di spec? Ti fidi della memoria del modello? Hai un flusso che funziona? Raccontamelo nei commenti — ho davvero voglia di sentire come altre persone stanno risolvendo questo stesso problema.
E se vuoi provarlo, il codice è tutto aperto: clona, prova e contribuisci su GitHub. Feedback e PR sono molto benvenuti.