L’IA a changé ma façon de construire des logiciels
Ça fait un moment que je n’écris plus la majeure partie du code à la main. Je décris ce que je veux, je révise, je corrige le cap, et l’IA exécute. Ça a tout changé : ce qui prenait avant un après-midi à taper sort aujourd’hui en quelques minutes. La livraison a cessé d’être une question de combien d’heures je tiens assis pour devenir une question de à quel point je sais bien piloter la machine.
Mais tout gain de vitesse révèle un nouveau goulot d’étranglement. Et le mien est apparu vite.
Le goulot d’étranglement qui a pris sa place
Un agent de code n’a pas de mémoire entre les sessions. Quand je ferme le terminal et que je le rouvre demain, il n’a pas la moindre idée de ce qu’on a décidé hier, pourquoi on l’a décidé, ce qui était déjà prêt et ce qui manquait. Chaque session repart de zéro.
Tant que le travail restait petit, je pouvais garder ça en tête. Mais quand l’IA s’est mise à livrer vraiment vite, je me suis retrouvé avec plusieurs fronts ouverts en même temps — et la partie la plus difficile de ma journée n’était plus d’écrire du code. C’était de me souvenir de l’état des choses. Ce qui était décidé, ce qui dépendait de quoi, ce qui avait déjà été fait et ce qui était resté à moitié.
Autrement dit : la documentation a cessé d’être un luxe « pour plus tard » et est devenue ce qui maintient le projet en marche. Sans elle, l’IA délire — elle réécrit ce qui existait déjà, ignore une décision qu’on a prise la semaine dernière, exécute dans le mauvais ordre. La qualité de ce qu’elle livre s’est mise à dépendre directement de la qualité de l’organisation et de l’enregistrement du travail.
J’ai presque tout testé — et tout butait sur le même mur
Je ne me suis pas lancé tout de suite dans la réinvention de la roue. J’ai passé des mois à tester les plugins et les skills que la communauté créait justement pour résoudre ça : superpowers, GSD (get-shit-done), cavekit, entre autres.
Tous ont du mérite. Ce sont des projets bien pensés, pleins de bonnes idées sur la manière de donner du processus et de la discipline à un agent. J’ai beaucoup appris de chacun. Mais, au final, tous butaient sur le même problème de fond : la façon de conserver ce que l’IA « sait » était un tas de fichiers de spec en Markdown commités dans le dépôt.
Et ça, en pratique, fait mal de deux façons :
- Ça pollue le git. Chaque planification devient une poignée de
.mdqui montent en même temps que le code. L’historique se remplit de bruit de processus, et le dépôt traîne une couche de paperasse qui n’est pas, à proprement parler, le produit. - Ça se périme vite. Une spec est la photo d’un instant. Le lendemain, la réalité a déjà changé, mais le fichier est toujours là, affirmant avec assurance des choses qui ne tiennent plus. Du coup, l’IA lit un vieux plan comme si c’était la vérité et le délire ne fait qu’empirer.
Je voulais l’opposé d’un fichier statique : je voulais un état vivant, que l’IA consulte et mette à jour au fil du travail — et non plus un document qui vieillit tout seul dans un coin du dépôt.
Et si le board appartenait à l’IA elle-même ?
C’est là que l’idée m’est venue. Toute équipe logicielle a déjà résolu le problème du « quoi faire, pourquoi et dans quel ordre » — ça s’appelle un tableau de tâches. Jira, Trello, Linear. Pourquoi l’IA n’aurait-elle pas le sien ?
Mais avec une inversion importante : ce board serait utilisé majoritairement par l’IA elle-même, via MCP (le protocole qui permet à l’agent de consulter et d’éditer des outils externes). L’agent lit le sprint actif, prend le prochain card, enregistre les décisions, attache le commit, ferme la tâche. Et moi — l’humain — j’entre par l’interface principalement pour suivre et réviser : voir ce qui est fait en temps réel, glisser des cards, laisser un commentaire qu’il lira à la prochaine session.
Ce n’est pas l’IA qui utilise un outil d’humain. C’est un outil conçu pour l’IA, avec une fenêtre par laquelle l’humain peut regarder à l’intérieur.
C’est ainsi qu’est né claude-organizer
claude-organizer est ce qui est sorti de cette idée. Ce n’est pas qu’un board : c’est tout un écosystème autour de l’organisation du travail de l’agent. Il y a des projets, des sprints, des histoires et des sous-tâches, des blockers, des tags, des priorités — et une interface en Nuxt qui reflète tout ça en temps réel, avec mise à jour via WebSocket pendant que l’IA travaille.
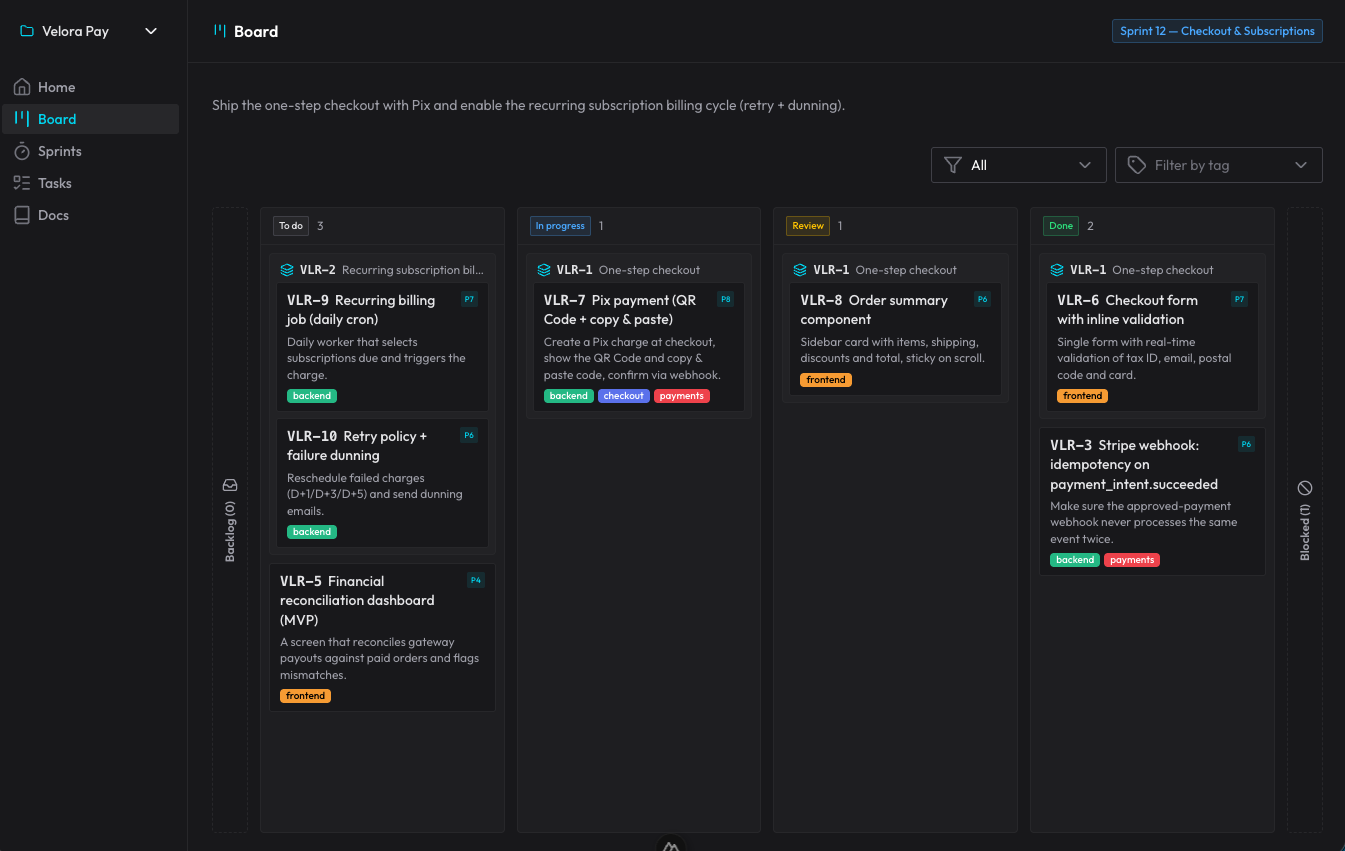
Tout le flux se déroule via skills + MCP. Il y a cinq skills qui se déclenchent à partir de ce que je dis, sans que j’en appelle aucune à la main : une pour orienter et opérer le board, une pour planifier une nouvelle demande en sprint/histoires/tâches, une pour exécuter un card tout au long de son cycle de vie, une de review (un gate obligatoire, exécuté par un sous-agent vierge, qui vérifie les critères d’acceptation et traque les bugs), et une d’autopilot pour avancer toute seule à travers plusieurs cards prêts. La documentation durable — architecture, décisions (ADRs), conventions — vit dans les docs de l’organizer lui-même, que l’IA lit avant de réinventer.
Comment il fonctionne en pratique
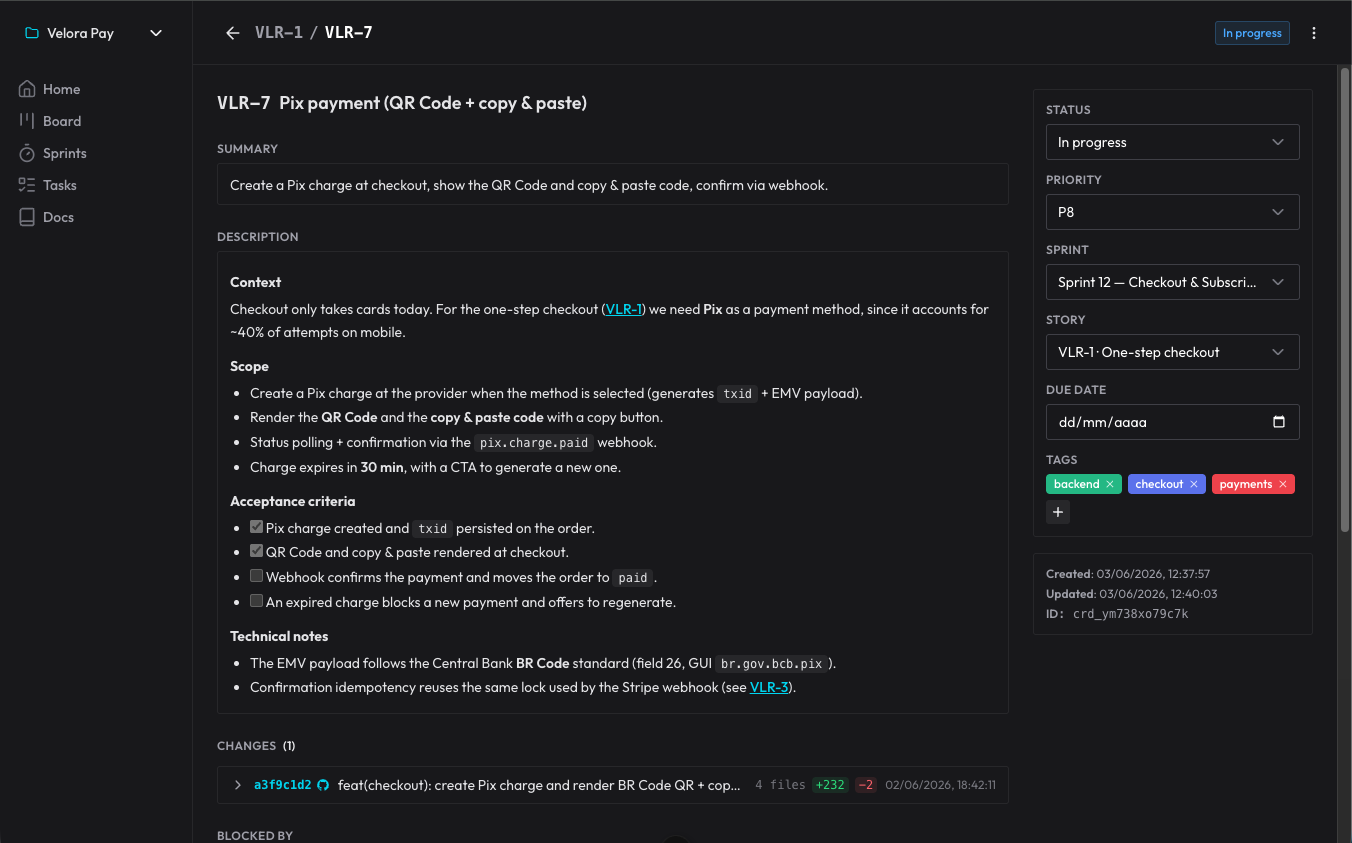
Le déclic, pour moi, a été celui-ci : comme ce qui a été planifié vit dans l’organizer et non dans la session, je peux exécuter chaque tâche dans une session totalement vierge, sans perdre en qualité. L’agent ouvre, lit le board, comprend où il en est, fait le travail. Peu importe que le contexte précédent se soit déjà évaporé — le plan n’était pas dans sa tête, il était dans la base.
Ça résout d’un coup les deux fantômes : l’ordre d’exécution (ce qui dépend de quoi est explicite dans les blockers) et le délire (il part de ce qui a été décidé, pas d’un vague souvenir). Et ça me laisse mener plusieurs fronts en même temps, en séquentiel ou en parallèle, sans me perdre.
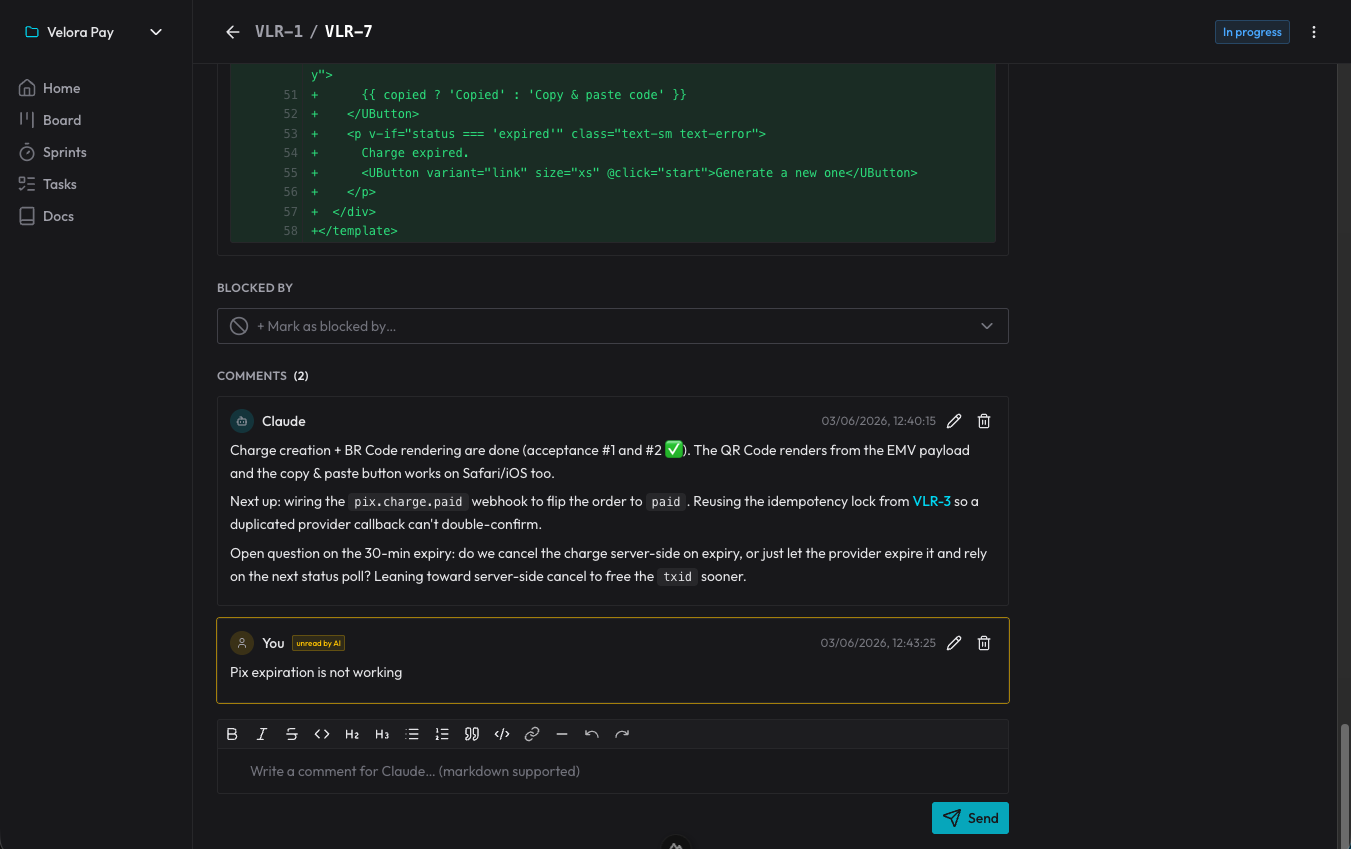
Les décisions ne se perdent pas parce qu’elles deviennent des commentaires sur le card : l’agent enregistre pourquoi il a fait d’une certaine façon, et je réponds là. À la session suivante, il lit les commentaires qu’il n’avait pas encore vus et reprend à partir de ce point. C’est un registre de décisions qui survit à la fin de chaque conversation.
L’effet de bord le plus agréable : le dépôt est redevenu uniquement le produit. Fini les dossiers de spec qui font grossir le git. Le « quoi faire et pourquoi » habite dans l’organizer, accessible depuis n’importe quelle session ; le code habite dans le dépôt. Chaque chose à sa place.
Comment démarrer
Il tourne comme plugin de Claude Code (les cinq skills + le serveur MCP), avec toute la stack en Docker. Pour le lancer :
1. Lancez la stack (Postgres + migrations + API + UI + MCP, d’un coup) :
git clone https://github.com/fmilioni/claude-organizer.git
cd claude-organizer
cp .env.example .env
docker compose up -d --buildL’UI est sur http://localhost:4401, l’API sur :4400 et le MCP sur :4402/mcp. Les migrations s’exécutent toutes seules avant que l’API ne démarre.
2. Installez le plugin — il livre les skills et enregistre le MCP, sans avoir besoin de claude mcp add :
/plugin marketplace add fmilioni/claude-organizer
/plugin install claude-organizer@claude-organizer3. Parlez avec Claude. Il suffit de parler. « Je veux planifier telle fonctionnalité » déclenche la skill de planification ; « on continue, c’est quoi la suite ? » fait que l’IA lit le board et reprend là où elle s’était arrêtée. Les skills se déclenchent à partir de ce que vous dites — vous n’avez besoin de mémoriser aucune commande.
Le projet est open source (MIT). On peut le faire tourner 100 % en local avec Docker ou l’héberger sur un VPS et y pointer Claude Code.
Je veux savoir comment vous organisez ça
C’est, au fond, la passerelle qui m’intéresse le plus : amener la discipline de processus que l’ingénierie possède déjà à l’intérieur de la nouvelle façon de construire, avec l’IA au volant. claude-organizer est ma tentative de combler ce trou — et il est né d’une douleur réelle, celle de voir du bon travail se perdre d’une session à l’autre.
Et vous, comment gérez-vous ça ? Vous balancez tout dans un fichier de spec ? Vous faites confiance à la mémoire du modèle ? Vous avez un flux qui fonctionne ? Racontez-moi dans les commentaires — j’ai très envie d’entendre comment d’autres personnes résolvent ce même problème.
Et si vous voulez l’essayer, le code est entièrement ouvert : clonez, testez et contribuez sur GitHub. Feedback et PR sont les bienvenus.