La IA cambió la forma en que construyo software
Hace un tiempo que ya no escribo a mano la mayor parte del código. Describo lo que quiero, lo reviso, corrijo el rumbo, y la IA ejecuta. Eso lo cambió todo: lo que antes llevaba una tarde de tecleo hoy sale en minutos. Entregar dejó de ser una cuestión de cuántas horas aguanto sentado y pasó a ser una cuestión de qué tan bien soy capaz de conducir la máquina.
Pero toda ganancia de velocidad expone un cuello de botella nuevo. Y el mío apareció rápido.
El cuello de botella que ocupó su lugar
Un agente de código no tiene memoria entre sesiones. Cuando cierro la terminal y la abro de nuevo mañana, no tiene la menor idea de lo que decidimos ayer, por qué lo decidimos, qué ya estaba listo y qué faltaba. Cada sesión empieza desde cero.
Mientras el trabajo era pequeño, podía sostener todo eso en la cabeza. Pero cuando la IA empezó a entregar rápido de verdad, me encontré con varios frentes abiertos al mismo tiempo — y la parte más difícil de mi día ya no era escribir código. Era recordar el estado de las cosas. Qué estaba decidido, qué dependía de qué, qué ya se había hecho y qué había quedado a medias.
Es decir: la documentación dejó de ser un lujo “para después” y pasó a ser lo que sostiene el proyecto en marcha. Sin ella, la IA delira — reescribe lo que ya existía, ignora una decisión que tomamos la semana pasada, ejecuta en el orden equivocado. La calidad de lo que entrega pasó a depender directamente de qué tan bien está organizado y registrado el trabajo.
Probé casi todo — y todos chocaban con el mismo muro
No me lancé directo a reinventar la rueda. Pasé meses probando los plugins y skills que la comunidad venía creando justamente para resolver esto: superpowers, GSD (get-shit-done), cavekit, entre otros.
Todos tienen mérito. Son proyectos bien pensados, llenos de buenas ideas sobre cómo darle proceso y disciplina a un agente. Aprendí bastante con cada uno. Pero, al final, todos chocaban con el mismo problema de fondo: la forma de guardar lo que la IA “sabe” era un montón de archivos de spec en Markdown commiteados en el repositorio.
Y eso, en la práctica, duele de dos maneras:
- Contamina el git. Cada planificación se vuelve un puñado de
.mdque sube junto con el código. El historial se llena de ruido de proceso, y el repositorio carga una capa de papeleo que no es, en realidad, el producto. - Se desactualiza rápido. Un spec es una foto de un momento. Al día siguiente la realidad ya cambió, pero el archivo sigue ahí, afirmando con confianza cosas que ya no valen. Entonces la IA lee un plan viejo como si fuera verdad y el delirio solo empeora.
Yo quería lo opuesto a un archivo estático: quería un estado vivo, que la IA consultara y actualizara a medida que el trabajo avanza — y no un documento más envejeciendo solo en un rincón del repo.
¿Y si el tablero fuera de la propia IA?
Ahí fue cuando se me ocurrió la idea. Todo equipo de software ya resolvió el problema de “qué hacer, por qué y en qué orden” — se llama tablero de tareas. Jira, Trello, Linear. ¿Por qué la IA no tendría el suyo?
Solo que con una inversión importante: ese tablero sería usado mayoritariamente por la propia IA, vía MCP (el protocolo que le permite al agente consultar y editar herramientas externas). El agente lee el sprint activo, toma la siguiente tarjeta, registra las decisiones, adjunta el commit, cierra la tarea. Y yo — el humano — entro por la interfaz principalmente para acompañar y revisar: ver qué se está haciendo en tiempo real, arrastrar tarjetas, dejar un comentario que él lee en la siguiente sesión.
No es la IA usando una herramienta de humano. Es una herramienta diseñada para la IA, con una ventana para que el humano mire dentro.
Así nació claude-organizer
claude-organizer es lo que salió de esa idea. No es solo un tablero: es un ecosistema alrededor de organizar el trabajo del agente. Tiene proyectos, sprints, historias y sub-tareas, blockers, etiquetas, prioridades — y una interfaz en Nuxt que refleja todo eso en tiempo real, actualizándose por WebSocket mientras la IA trabaja.
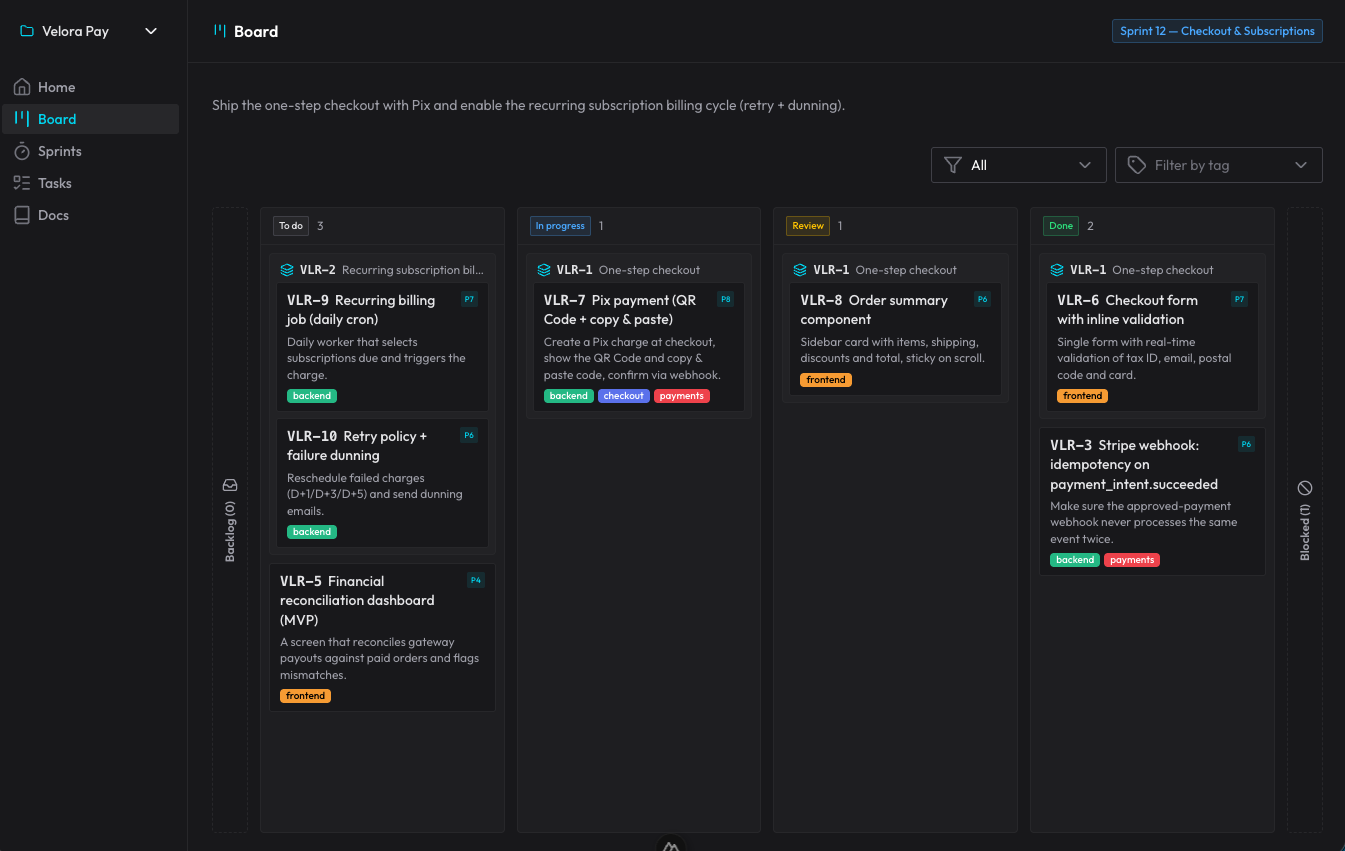
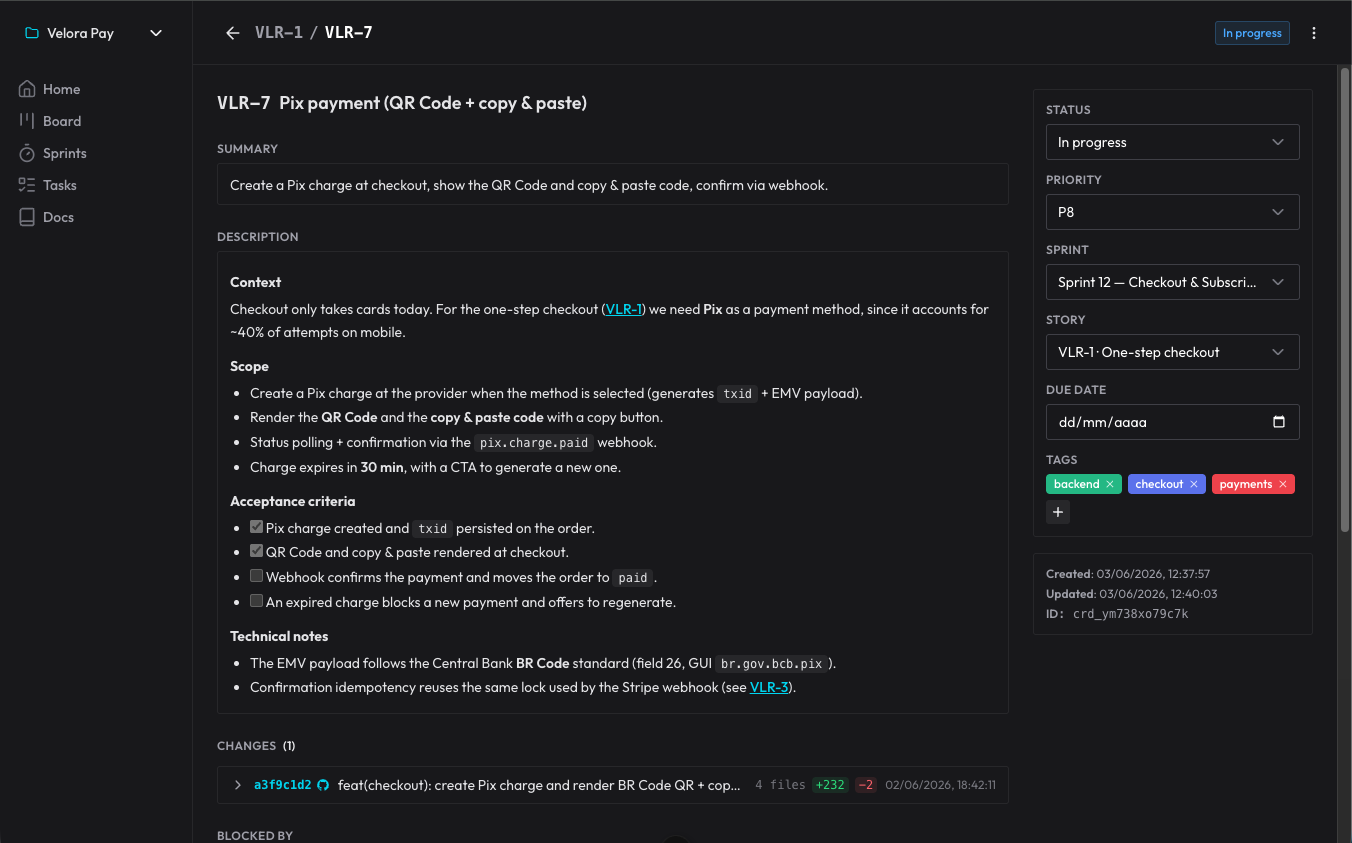
El flujo entero ocurre por skills + MCP. Son cinco skills que se disparan por lo que digo, sin que yo llame ninguna a mano: una para orientar y operar el tablero, una para planificar una demanda nueva en sprint/historias/tareas, una para ejecutar una tarjeta por su ciclo de vida, una de review (un gate obligatorio, ejecutado por un subagente limpio, que verifica los criterios de aceptación y caza bugs), y una de autopilot para avanzar sola por varias tarjetas listas. La documentación duradera — arquitectura, decisiones (ADRs), patrones — vive en los docs del propio organizer, que la IA lee antes de reinventar.
Cómo funciona en la práctica
El verdadero punto de inflexión, para mí, fue este: como lo que se planificó vive en el organizer y no en la sesión, puedo ejecutar cada tarea en una sesión completamente limpia, sin perder calidad. El agente abre, lee el tablero, entiende dónde está, hace el trabajo. No importa si el contexto anterior ya se evaporó — el plan no estaba en su cabeza, estaba en la base de datos.
Eso resuelve de una vez los dos fantasmas: el orden de ejecución (qué depende de qué está explícito en los blockers) y el delirio (parte de lo que se decidió, no de un recuerdo vago). Y me deja llevar varios frentes al mismo tiempo, en secuencia o en paralelo, sin perderme.
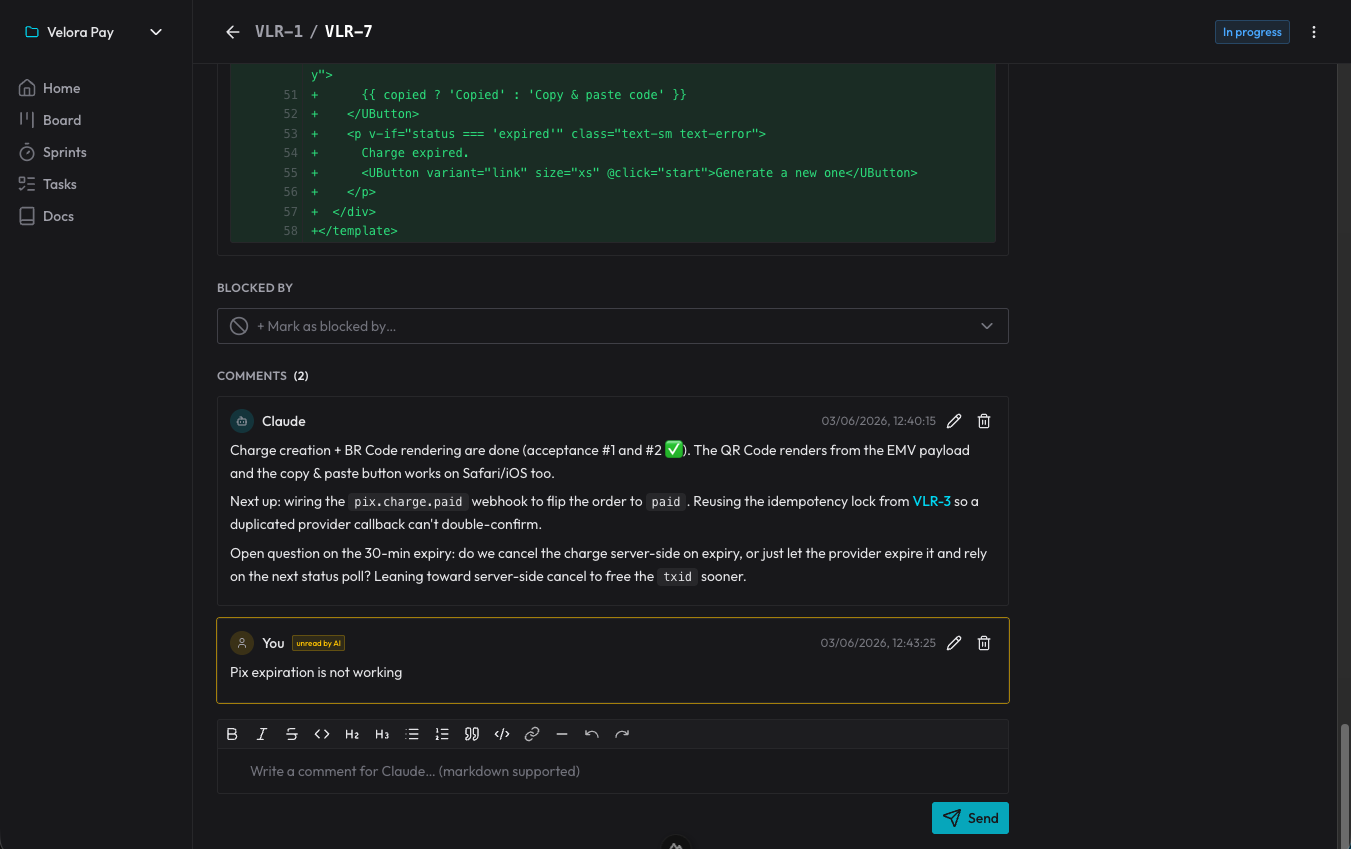
Las decisiones no se pierden porque se vuelven comentarios en la tarjeta: el agente registra por qué lo hizo de cierta forma, y yo respondo ahí mismo. En la sesión siguiente, lee los comentarios que aún no había visto y sigue desde ese punto. Es un registro de decisiones que sobrevive al final de cada conversación.
El efecto colateral más rico: el repositorio volvió a ser solo el producto. Nada de carpetas de spec engordando el git. El “qué hacer y por qué” vive en el organizer, accesible desde cualquier sesión; el código vive en el repo. Cada cosa en su lugar.
Cómo empezar
Corre como plugin de Claude Code (las cinco skills + el servidor MCP), con todo el stack en Docker. Para levantarlo:
1. Levanta el stack (Postgres + migraciones + API + UI + MCP, de una sola vez):
git clone https://github.com/fmilioni/claude-organizer.git
cd claude-organizer
cp .env.example .env
docker compose up -d --buildLa UI queda en http://localhost:4401, la API en :4400 y el MCP en :4402/mcp. Las migraciones corren solas antes de que la API arranque.
2. Instala el plugin — entrega las skills y registra el MCP, sin necesidad de claude mcp add:
/plugin marketplace add fmilioni/claude-organizer
/plugin install claude-organizer@claude-organizer3. Habla con Claude. Solo díselo. “Quiero planificar tal funcionalidad” dispara la skill de planificación; “sigamos, ¿qué es lo próximo?” hace que la IA lea el tablero y retome donde quedó. Las skills se disparan por lo que dices — no necesitas memorizar ningún comando.
El proyecto es open source (MIT). Puedes correrlo 100% local con Docker o alojarlo en un VPS y apuntar Claude Code hacia allí.
Quiero saber cómo organizas esto
Esta es, en el fondo, la conexión que más me interesa: traer la disciplina de proceso que la ingeniería ya tiene hacia la nueva forma de construir, con la IA al volante. claude-organizer es mi intento de cerrar ese hueco — y nació de un dolor real, de ver buen trabajo perderse entre una sesión y otra.
¿Y tú, cómo vienes lidiando con esto? ¿Tiras todo a un archivo de spec? ¿Confías en la memoria del modelo? ¿Tienes algún flujo que funcione? Cuéntame en los comentarios — me encantaría escuchar cómo otras personas están resolviendo este mismo problema.
Y si quieres probarlo, el código está todo abierto: clónalo, pruébalo y contribuye en GitHub. El feedback y los PR son muy bienvenidos.