AI 改变了我构建软件的方式
有一阵子我已经不再亲手写大部分代码了。我描述我想要什么,做审阅,纠正方向,然后由 AI 来执行。这改变了一切:以前要敲一下午的活儿,现在几分钟就出来了。交付不再取决于我能坐多少个小时,而是取决于我能多好地驾驭这台机器。
但每一次提速都会暴露出一个新的瓶颈。我的瓶颈很快就冒出来了。
取而代之冒出来的瓶颈
代码智能体在不同会话之间是没有记忆的。当我关掉终端,明天再打开时,它对我们昨天决定了什么、为什么这么定、哪些已经做完、哪些还没做,统统一无所知。每一次会话都从零开始。
工作量小的时候,这些还能装在脑子里。但当 AI 真正开始快速交付,我发现自己同时开着好几条战线——而我一天里最难的部分不再是写代码,而是记住事情的状态。什么已经定了,什么依赖什么,什么已经做完,什么做了一半。
也就是说:文档不再是”以后再说”的奢侈品,而成了支撑项目往前走的东西。没有它,AI 就会胡来——重写已经存在的东西,无视我们上周做的某个决定,按错误的顺序执行。它交付的质量,开始直接取决于工作被组织和记录得有多好。
我几乎全试了一遍——结果都撞上同一堵墙
我没有一上来就重新造轮子。我花了几个月去试社区为解决这个问题而做的那些插件和 skill:superpowers、GSD(get-shit-done)、cavekit 等等。
它们都有可取之处。这些项目都经过深思熟虑,对如何给一个智能体注入流程和纪律,充满了好点子。我从每一个里都学到了不少。但归根结底,它们都撞上了同一个根本问题:保存 AI “知道”的东西的方式,是一堆提交进代码仓库的 Markdown 规格文件。
这在实践中有两重痛处:
- 污染 git。 每一次规划都变成一把
.md文件,跟着代码一起提交。历史记录里塞满了流程的噪音,仓库背上了一层并不属于产品本身的文书。 - 很快就过时。 规格只是某个时刻的快照。第二天现实已经变了,但那个文件还在那儿,理直气壮地宣称着早已不成立的东西。然后 AI 把一份旧计划当成事实来读,胡言乱语就更严重了。
我想要的恰恰是静态文件的反面:我想要一个活的状态,AI 随着工作推进去查询、去更新——而不是又一份独自在仓库角落里慢慢老去的文档。
如果这块看板是 AI 自己的呢?
就在那时,这个想法冒了出来。每一个软件团队都已经解决过”做什么、为什么做、按什么顺序做”的问题——这东西叫任务看板。Jira、Trello、Linear。AI 凭什么不能有自己的一块?
只不过有一个重要的倒转:这块看板主要由 AI 自己使用,通过 MCP(让智能体能查询和编辑外部工具的协议)。智能体读取当前活跃的 sprint,取下一个卡片,记录决策,附上 commit,关闭任务。而我——这个人类——主要是通过界面进来跟进和审阅:实时看着正在做什么,拖动卡片,留下一条它会在下次会话里读到的评论。
这不是 AI 在用一个为人类设计的工具。这是一个为 AI 设计的工具,外加一扇供人类往里看的窗。
claude-organizer 就是这么诞生的
claude-organizer 就是这个想法做出来的成果。它不只是一块看板:它是围绕”组织智能体工作”建起来的一整个生态。它有项目、sprint、故事和子任务、blocker、标签、优先级——还有一个用 Nuxt 做的界面,实时镜像这一切,在 AI 工作的同时通过 WebSocket 更新。
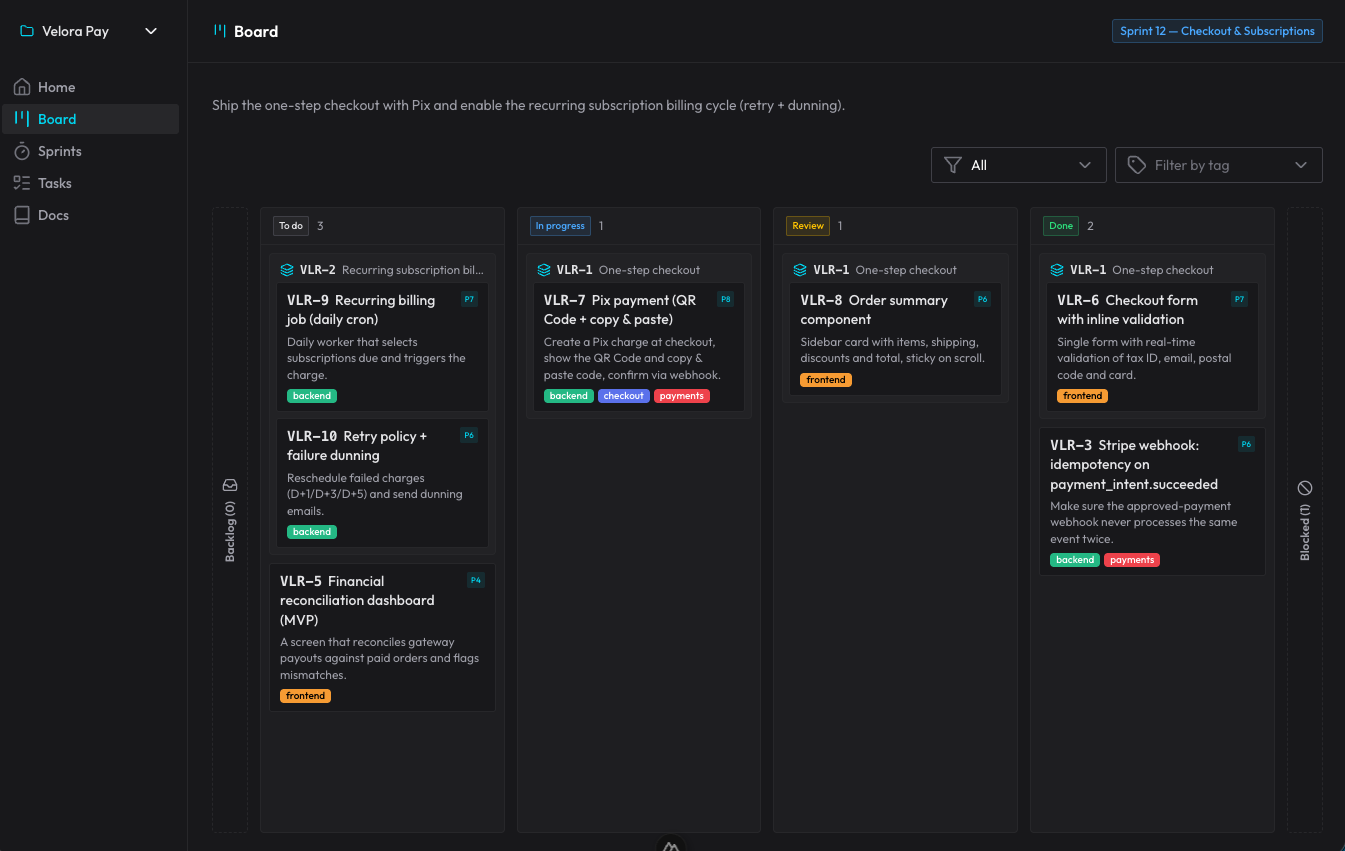
整个流程通过 skill + MCP 运转。一共有五个 skill,靠我说的话来触发,不用我手动调用任何一个:一个用来给看板引路和操作,一个用来把一项新需求规划成 sprint/故事/任务,一个用来按生命周期执行某个卡片,一个负责审阅(一道必经的关卡,由一个干净的子智能体运行,核对验收标准并捕捉 bug),还有一个 autopilot 用来自动推进好几个就绪的卡片。持久的文档——架构、决策(ADR)、规范——都住在 organizer 自己的 docs 里,AI 在重新发明之前会先去读。
它在实践中是怎么工作的
对我来说,关键的转折在于:因为规划好的东西活在 organizer 里而不是会话里,我可以在一个完全干净的会话里执行每个任务,而不损失质量。智能体打开,读看板,搞清楚自己在哪儿,然后干活。哪怕之前的上下文早已蒸发——计划本来就不在它脑子里,而在数据库里。
这一下子就解决了两个幽灵:执行顺序(什么依赖什么在 blocker 里写得明明白白)和胡言乱语(它从已经决定的东西出发,而不是从一段模糊的记忆出发)。它还让我能同时推进好几条战线,无论是串行还是并行,都不会乱。
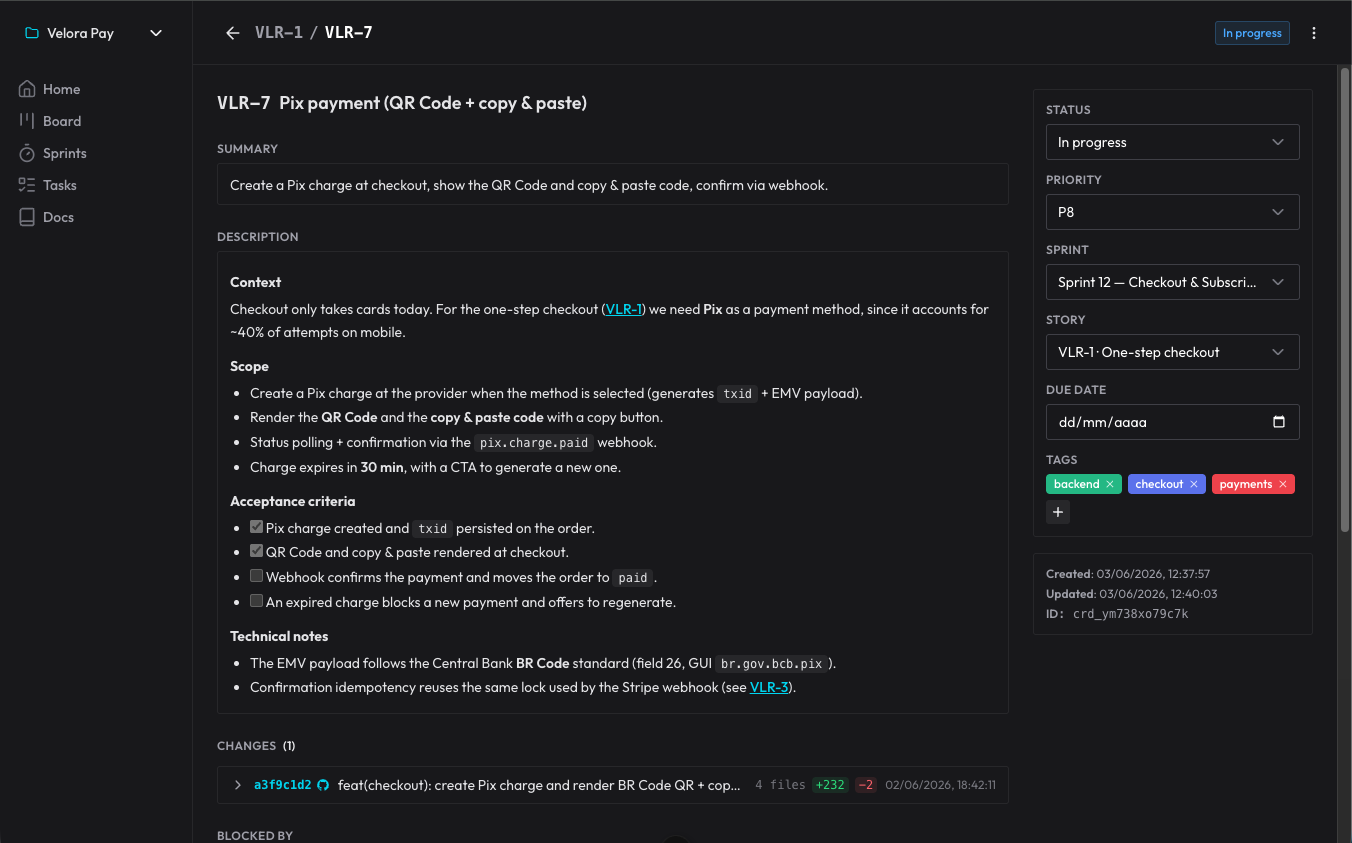
决策不会丢失,因为它们变成了卡片上的评论:智能体记录下为什么这么做,我在那里回复。下一次会话时,它会读还没看过的评论,然后从那个点继续。这是一份能挺过每一次对话结束的决策记录。
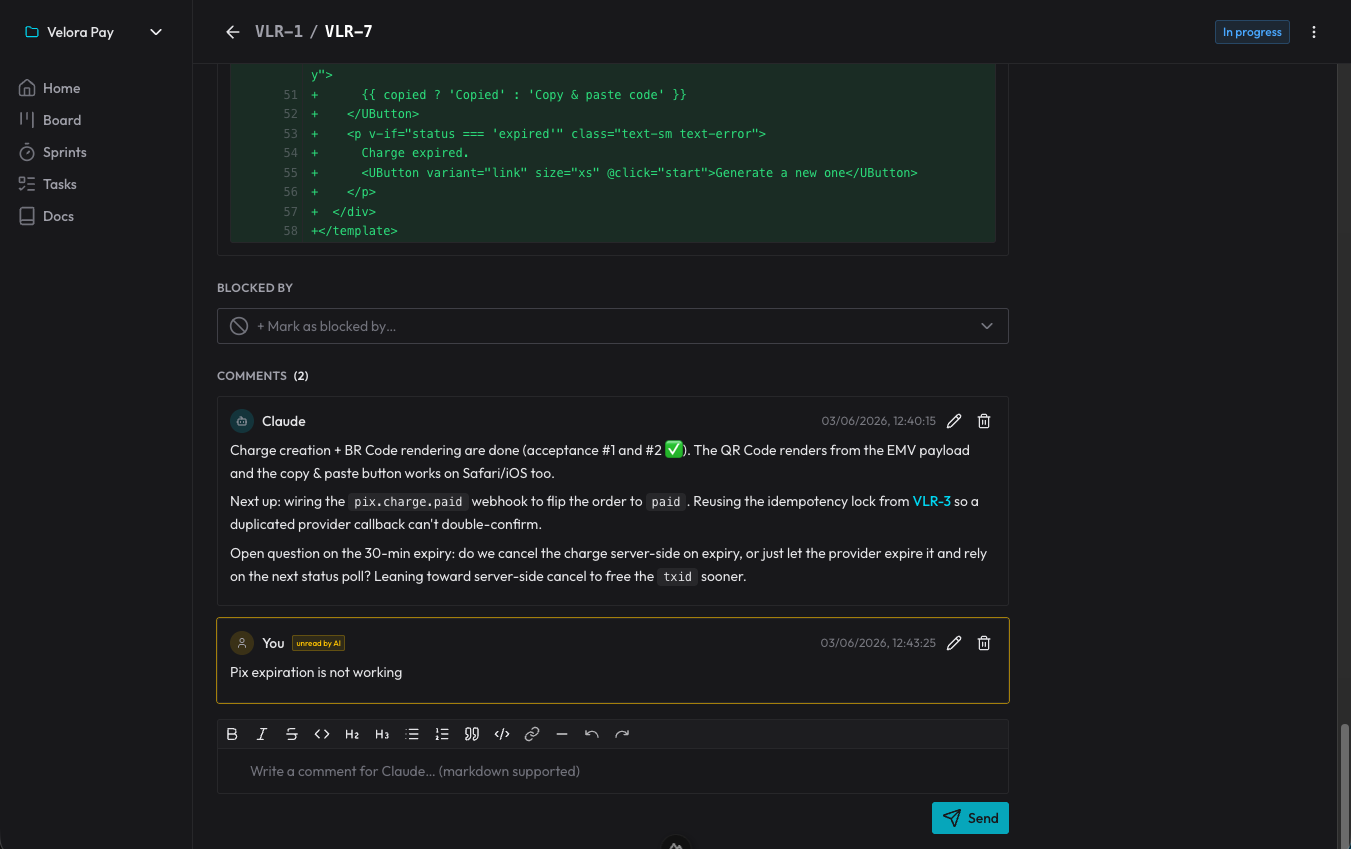
最舒服的副作用是:仓库重新变回了只装产品。 没有一堆撑大 git 的规格文件夹。“做什么、为什么”住在 organizer 里,任何会话都能访问;代码住在仓库里。各归各位。
怎么上手
它作为 Claude Code 的插件运行(五个 skill + MCP 服务器),整套技术栈都在 Docker 里。要跑起来:
1. 启动技术栈(Postgres + migration + API + UI + MCP,一次到位):
git clone https://github.com/fmilioni/claude-organizer.git
cd claude-organizer
cp .env.example .env
docker compose up -d --buildUI 在 http://localhost:4401,API 在 :4400,MCP 在 :4402/mcp。migration 会在 API 启动前自动跑。
2. 安装插件——它会交付 skill 并注册 MCP,不需要 claude mcp add:
/plugin marketplace add fmilioni/claude-organizer
/plugin install claude-organizer@claude-organizer3. 和 Claude 对话。 说话就行。“我想规划某个功能”会触发规划的 skill;“我们继续吧,下一个是什么?“会让 AI 读看板并从停下的地方接着走。skill 靠你说的话来触发——你不用背任何命令。
这个项目是开源的(MIT)。可以用 Docker 在本地 100% 跑起来,也可以部署到一台 VPS 上,让 Claude Code 指向那里。
我想知道你是怎么组织的
说到底,这是我最感兴趣的那座桥:把工程领域早已具备的流程纪律,带进这种由 AI 掌舵的全新构建方式里。claude-organizer 是我填补这个空洞的尝试——而它诞生于一个真实的痛点:眼看着好的工作在一次又一次会话之间丢失。
那你呢,最近是怎么应对这件事的?把所有东西都丢进一个规格文件?信任模型的记忆?有什么管用的流程吗?在评论区告诉我吧——我很想听听别人是怎么解决这同一个问题的。
如果你想试试,代码全都开放:去 GitHub 克隆、试用并贡献。非常欢迎反馈和 PR。