AI는 내가 소프트웨어를 만드는 방식을 바꿨다
코드의 대부분을 직접 손으로 짠 지 꽤 됐다. 나는 원하는 것을 설명하고, 검토하고, 방향을 바로잡고, AI가 실행한다. 이것이 모든 걸 바꿨다. 예전에는 오후 내내 타이핑해야 했던 일이 지금은 몇 분 만에 나온다. 산출은 더 이상 내가 얼마나 오래 앉아 있을 수 있느냐의 문제가 아니라, 내가 기계를 얼마나 잘 운전할 수 있느냐의 문제가 되었다.
하지만 속도가 빨라질 때마다 새로운 병목이 드러난다. 그리고 내 병목은 금세 나타났다.
그 자리에 대신 나타난 병목
코드 에이전트는 세션 사이에 기억이 없다. 터미널을 닫고 내일 다시 열면, 에이전트는 우리가 어제 무엇을 결정했는지, 왜 결정했는지, 무엇이 이미 끝났고 무엇이 남았는지 전혀 모른다. 매 세션이 백지에서 시작한다.
작업이 작을 때는 머릿속으로 붙들고 있을 수 있었다. 하지만 AI가 정말로 빠르게 결과를 내놓기 시작하자, 나는 동시에 여러 전선을 열어 둔 상태가 됐고, 하루 중 가장 어려운 부분은 더 이상 코드를 쓰는 일이 아니었다. 상태를 기억하는 일이었다. 무엇이 결정됐고, 무엇이 무엇에 의존하며, 무엇이 이미 됐고 무엇이 반쯤 남았는지.
다시 말해, 문서화는 “나중에 할” 사치품이기를 멈추고 프로젝트를 굴러가게 받쳐 주는 토대가 되었다. 그게 없으면 AI는 헛소리를 한다. 이미 있던 것을 다시 짜고, 지난주에 우리가 내린 결정을 무시하며, 잘못된 순서로 실행한다. AI가 내놓는 결과의 품질은 작업이 얼마나 잘 정리되고 기록되어 있는지에 직접 좌우되기 시작했다.
거의 다 시험해 봤다 — 그리고 모두 같은 벽에 부딪혔다
나는 곧장 바퀴를 다시 발명하러 나서지 않았다. 바로 이 문제를 풀기 위해 커뮤니티가 만들어 온 플러그인과 스킬들을 몇 달간 시험했다. superpowers, GSD(get-shit-done), cavekit 등이다.
모두 나름의 가치가 있다. 잘 설계된 프로젝트들이고, 에이전트에 프로세스와 규율을 부여하는 좋은 아이디어가 가득하다. 각각에서 많이 배웠다. 하지만 결국 모두 같은 근본 문제에 부딪혔다. AI가 “아는 것”을 저장하는 방식이 저장소에 커밋된 한 무더기의 Markdown 스펙 파일이었던 것이다.
그리고 이것은 실제로 두 가지 방식으로 아프다.
- git을 오염시킨다. 계획 하나하나가 코드와 함께 올라가는
.md뭉치가 된다. 히스토리는 프로세스 노이즈로 가득 차고, 저장소는 사실상 제품이 아닌 서류 더미 한 겹을 짊어진다. - 빠르게 낡는다. 스펙은 한순간의 스냅사진이다. 다음 날이면 현실은 이미 바뀌었지만 파일은 그대로 남아, 더는 유효하지 않은 것들을 자신만만하게 단언한다. 그러면 AI는 오래된 계획을 진실인 양 읽고, 헛소리는 더 심해진다.
나는 정적인 파일의 정반대를 원했다. 작업이 진행되는 대로 AI가 참조하고 갱신하는 살아 있는 상태를 원했지, 저장소 구석에서 혼자 늙어가는 문서를 더는 원하지 않았다.
만약 그 보드가 AI 자신의 것이라면?
바로 그때 아이디어가 떠올랐다. 모든 소프트웨어 팀은 이미 “무엇을, 왜, 어떤 순서로 할 것인가”라는 문제를 해결해 두었다. 바로 작업 보드다. Jira, Trello, Linear. AI라고 자기 것을 갖지 못할 이유가 있나?
다만 한 가지 중요한 반전이 있다. 이 보드는 주로 AI 자신이 MCP(에이전트가 외부 도구를 조회하고 편집할 수 있게 해 주는 프로토콜)를 통해 사용한다. 에이전트는 활성 스프린트를 읽고, 다음 카드를 집어 들고, 결정을 기록하고, 커밋을 첨부하고, 작업을 닫는다. 그리고 인간인 나는 주로 지켜보고 검토하기 위해 인터페이스로 들어간다. 무엇이 만들어지고 있는지 실시간으로 보고, 카드를 끌어다 옮기고, 다음 세션에서 에이전트가 읽을 댓글을 남긴다.
이것은 AI가 인간용 도구를 쓰는 것이 아니다. AI를 위해 설계된 도구이며, 인간이 안을 들여다볼 수 있는 창이 하나 달린 것이다.
이렇게 claude-organizer가 탄생했다
claude-organizer는 그 아이디어에서 나온 결과물이다. 단순한 보드가 아니라, 에이전트의 작업을 정리하는 일을 둘러싼 하나의 생태계다. 프로젝트, 스프린트, 히스토리와 하위 작업, 블로커, 태그, 우선순위가 있고, 이 모든 것을 실시간으로 비추는 Nuxt 인터페이스가 있어 AI가 일하는 동안 WebSocket으로 갱신된다.
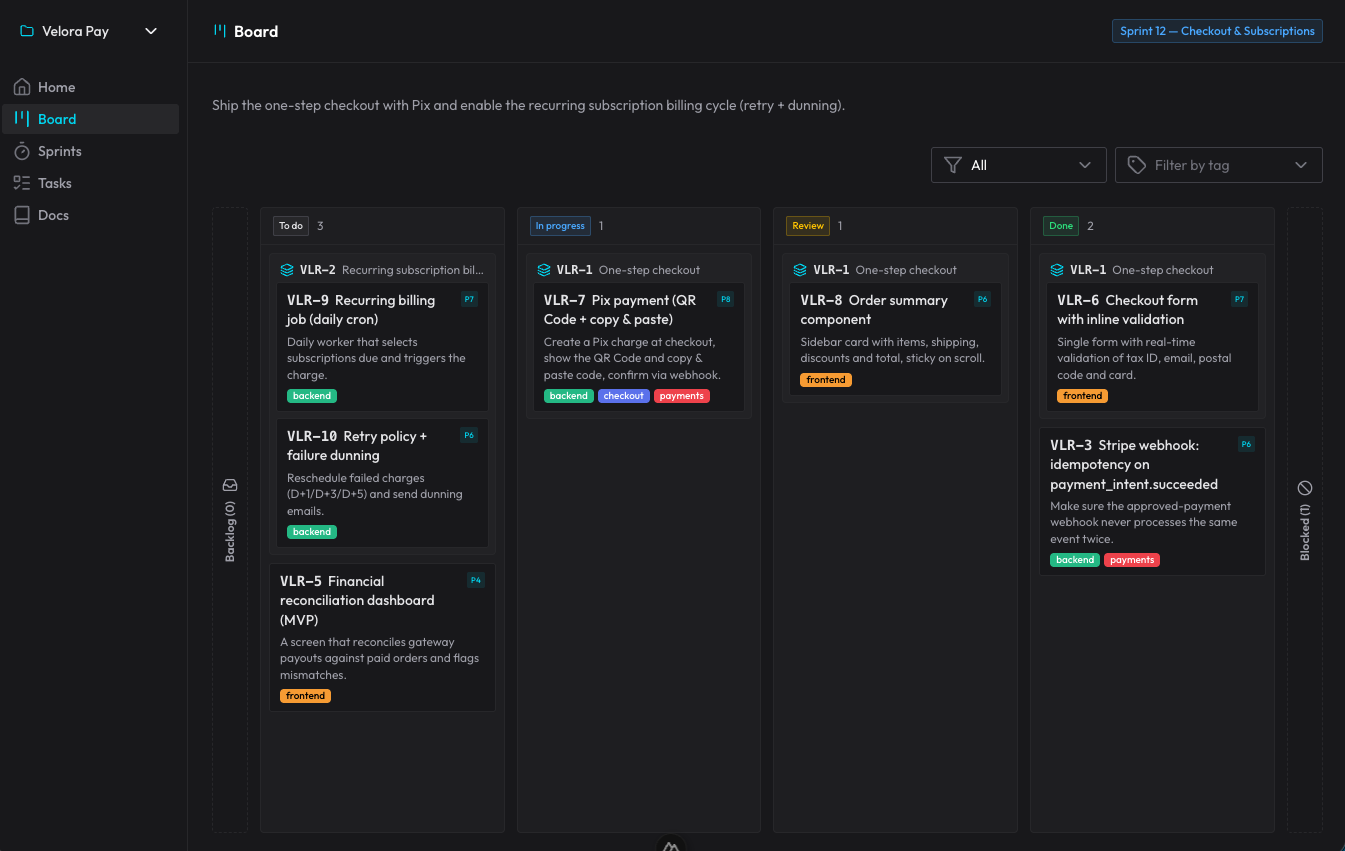
전체 흐름은 스킬 + MCP로 일어난다. 내가 말하는 것에 따라 발동하는 다섯 개의 스킬이 있고, 어느 하나도 손으로 부를 필요가 없다. 하나는 보드를 안내하고 운영하는 것, 하나는 새 요구사항을 스프린트/히스토리/작업으로 계획하는 것, 하나는 카드를 그 생애주기에 따라 실행하는 것, 하나는 리뷰(깨끗한 서브에이전트가 돌리는 필수 게이트로, 인수 기준을 확인하고 버그를 사냥한다), 그리고 하나는 준비된 여러 카드를 스스로 진행하는 오토파일럿이다. 지속적인 문서 — 아키텍처, 결정(ADR), 패턴 — 은 organizer 자체의 docs에 살며, AI는 바퀴를 다시 발명하기 전에 이를 읽는다.
실제로는 어떻게 작동하는가
내게 결정적인 전환점은 이것이었다. 계획된 것이 세션이 아니라 organizer에 살기 때문에, 나는 각 작업을 완전히 깨끗한 세션에서, 품질 손실 없이 실행할 수 있다. 에이전트가 열고, 보드를 읽고, 자기가 어디에 있는지 파악하고, 일을 한다. 이전 컨텍스트가 이미 증발했어도 상관없다. 계획은 에이전트의 머릿속이 아니라 데이터베이스에 있었으니까.
이것은 두 유령을 한 번에 해결한다. 실행 순서(무엇이 무엇에 의존하는지가 블로커에 명시되어 있다)와 헛소리(에이전트는 막연한 기억이 아니라 결정된 것에서 출발한다)다. 그리고 나는 여러 전선을 동시에, 순차적으로든 병렬로든 길을 잃지 않고 끌고 갈 수 있다.
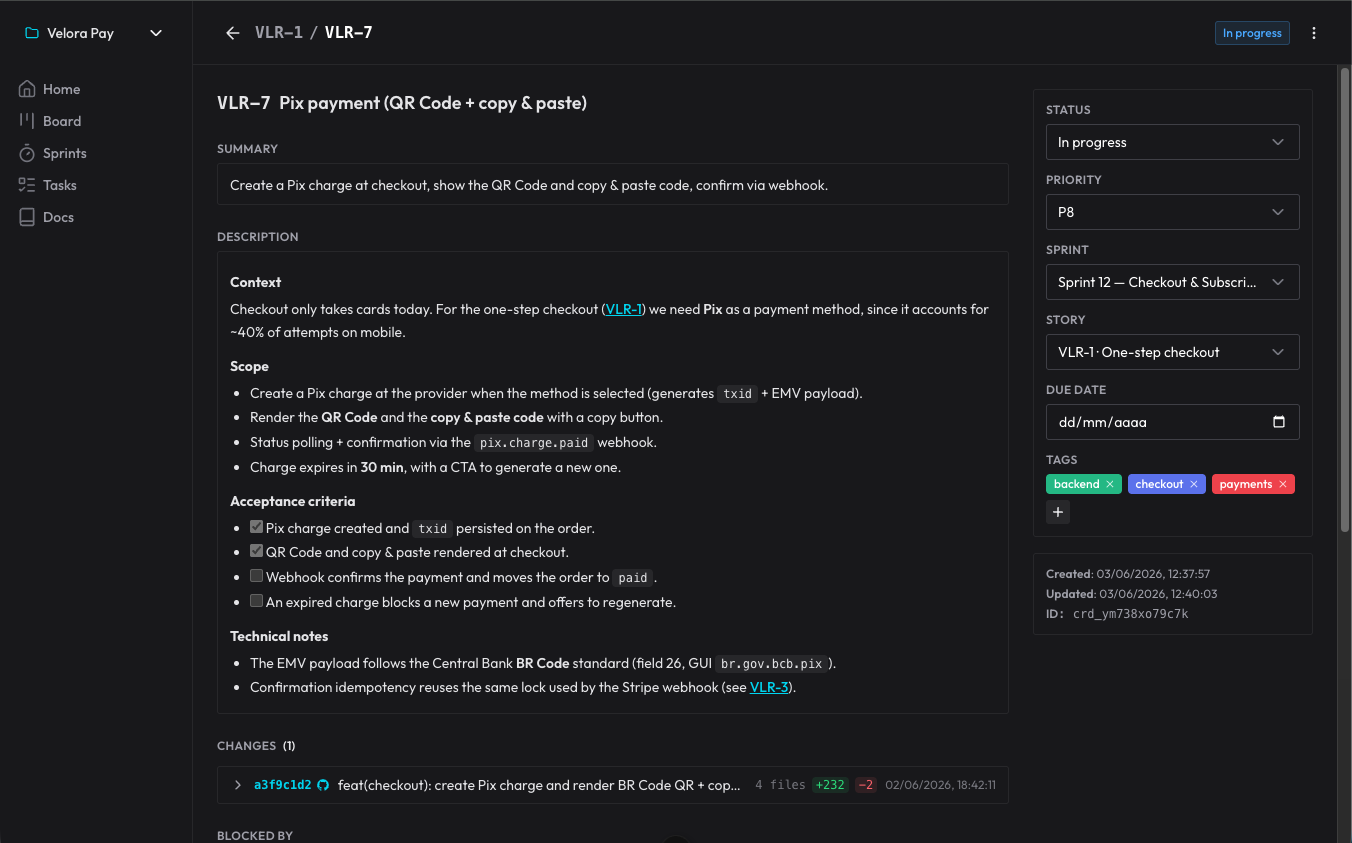
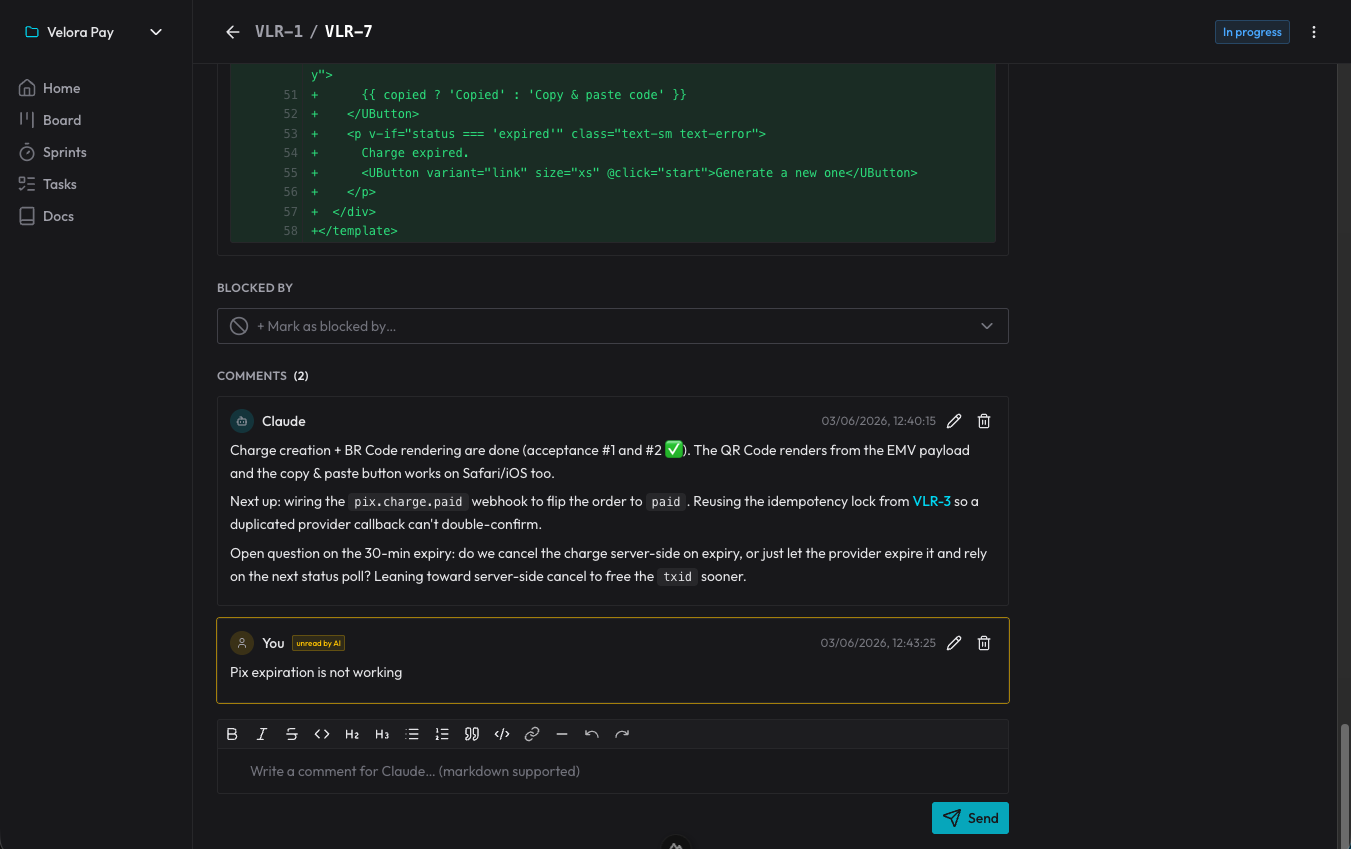
결정은 사라지지 않는다. 카드의 댓글이 되기 때문이다. 에이전트는 왜 그런 식으로 했는지 기록하고, 나는 거기에 답한다. 다음 세션에서 에이전트는 아직 보지 못한 댓글을 읽고 그 지점에서 이어 간다. 매 대화의 끝을 살아남는 결정 기록인 셈이다.
가장 기분 좋은 부수 효과는 이것이다. 저장소가 다시 제품 그 자체가 되었다. git을 살찌우는 스펙 폴더는 없다. “무엇을, 왜 할 것인가”는 organizer에 살며 어느 세션에서나 접근할 수 있고, 코드는 저장소에 산다. 각자 제자리에.
시작하는 법
이것은 Claude Code 플러그인(다섯 개의 스킬 + MCP 서버)으로 돌아가며, 전체 스택은 Docker에 담겨 있다. 띄우려면 이렇게 한다.
1. 스택을 띄운다(Postgres + 마이그레이션 + API + UI + MCP, 한 번에):
git clone https://github.com/fmilioni/claude-organizer.git
cd claude-organizer
cp .env.example .env
docker compose up -d --buildUI는 http://localhost:4401, API는 :4400, MCP는 :4402/mcp에 뜬다. 마이그레이션은 API가 올라오기 전에 알아서 돌아간다.
2. 플러그인을 설치한다 — 이것은 스킬을 가져오고 동시에 MCP를 등록하므로 claude mcp add가 필요 없다:
/plugin marketplace add fmilioni/claude-organizer
/plugin install claude-organizer@claude-organizer3. Claude와 대화한다. 그냥 말하면 된다. “이런 기능을 계획하고 싶어”는 계획 스킬을 발동하고, “계속하자, 다음은 뭐야?”는 AI가 보드를 읽고 멈췄던 곳에서 이어 가게 한다. 스킬은 당신이 말하는 것에 따라 발동한다 — 어떤 명령어도 외울 필요가 없다.
이 프로젝트는 오픈소스(MIT)다. Docker로 100% 로컬에서 돌릴 수도 있고, VPS에 호스팅한 뒤 Claude Code를 그쪽으로 가리키게 할 수도 있다.
당신은 이걸 어떻게 정리하는지 궁금하다
이것은 근본적으로 내가 가장 흥미를 느끼는 다리다. 엔지니어링이 이미 가진 프로세스의 규율을, AI가 운전대를 잡은 새로운 만드는 방식 안으로 가져오는 것. claude-organizer는 그 구멍을 메우려는 나의 시도이고, 세션과 세션 사이에서 좋은 작업이 사라지는 걸 보며 느낀 진짜 고통에서 태어났다.
당신은 어떤가, 이 문제를 어떻게 다루고 있는가? 모든 걸 스펙 파일 하나에 던져 넣는가? 모델의 기억에 의존하는가? 잘 작동하는 흐름이 있는가? 댓글에서 들려달라 — 다른 사람들이 이 같은 문제를 어떻게 풀고 있는지 정말 듣고 싶다.
그리고 시험해 보고 싶다면, 코드는 모두 열려 있다: GitHub에서 클론하고, 테스트하고, 기여하라. 피드백과 PR은 언제나 환영이다.