A IA mudou o jeito que eu construo software
Faz um tempo que eu não escrevo mais a maior parte do código na unha. Eu descrevo o que quero, reviso, corrijo o rumo, e a IA executa. Isso mudou tudo: o que antes levava uma tarde de digitação hoje sai em minutos. A entrega deixou de ser uma questão de quantas horas eu consigo ficar sentado e passou a ser uma questão de quão bem eu consigo dirigir a máquina.
Mas todo ganho de velocidade expõe um gargalo novo. E o meu apareceu rápido.
O gargalo que apareceu no lugar
Um agente de código não tem memória entre sessões. Quando eu fecho o terminal e abro de novo amanhã, ele não faz a menor ideia do que a gente decidiu ontem, por que decidiu, o que já estava pronto e o que faltava. Cada sessão começa do zero.
Enquanto o trabalho era pequeno, dava pra segurar isso na cabeça. Mas quando a IA passou a entregar rápido de verdade, eu me vi com várias frentes abertas ao mesmo tempo — e a parte mais difícil do meu dia não era mais escrever código. Era lembrar o estado das coisas. O que estava decidido, o que dependia do quê, o que já tinha sido feito e o que tinha ficado pela metade.
Ou seja: a documentação parou de ser um luxo “pra depois” e virou o que sustenta o projeto andando. Sem ela, a IA delira — reescreve o que já existia, ignora uma decisão que a gente tomou semana passada, executa na ordem errada. A qualidade do que ela entrega passou a depender diretamente de quão bem o trabalho está organizado e registrado.
Testei quase tudo — e todos batiam no mesmo muro
Eu não parti direto pra reinventar a roda. Passei meses testando os plugins e skills que a comunidade vinha criando exatamente pra resolver isso: o superpowers, o GSD (get-shit-done), o cavekit, entre outros.
Todos têm mérito. São projetos bem pensados, cheios de boas ideias sobre como dar processo e disciplina a um agente. Aprendi bastante com cada um. Mas, no fim, todos esbarravam no mesmo problema de fundo: a forma de guardar o que a IA “sabe” era um monte de arquivos de spec em Markdown commitados no repositório.
E isso, na prática, dói de duas formas:
- Polui o git. Cada planejamento vira um punhado de
.mdque sobe junto com o código. O histórico fica cheio de ruído de processo, e o repositório carrega uma camada de papelada que não é, de fato, o produto. - Defasa rápido. Spec é foto de um momento. No dia seguinte a realidade já mudou, mas o arquivo continua lá, afirmando com confiança coisas que não valem mais. Aí a IA lê um plano velho como se fosse verdade e o delírio só piora.
Eu queria o oposto de um arquivo estático: queria um estado vivo, que a IA consultasse e atualizasse conforme o trabalho anda — e não mais um documento que envelhece sozinho no canto do repo.
E se a board fosse da própria IA?
Foi aí que me veio a ideia. Todo time de software já resolveu o problema de “o que fazer, por quê e em que ordem” — chama-se quadro de tarefas. Jira, Trello, Linear. Por que a IA não teria o dela?
Só que com uma inversão importante: essa board seria usada majoritariamente pela própria IA, via MCP (o protocolo que deixa o agente consultar e editar ferramentas externas). O agente lê o sprint ativo, pega o próximo card, registra as decisões, anexa o commit, fecha a tarefa. E eu — o humano — entro pela interface principalmente pra acompanhar e revisar: ver o que está sendo feito em tempo real, arrastar cards, deixar um comentário que ele lê na próxima sessão.
Não é a IA usando uma ferramenta de humano. É uma ferramenta desenhada pra IA, com uma janela pro humano olhar dentro.
Foi assim que nasceu o claude-organizer
O claude-organizer é o que saiu dessa ideia. Não é só uma board: é um ecossistema em volta de organizar o trabalho do agente. Tem projetos, sprints, histórias e sub-tarefas, blockers, tags, prioridades — e uma interface em Nuxt que espelha tudo isso em tempo real, com atualização via WebSocket enquanto a IA trabalha.
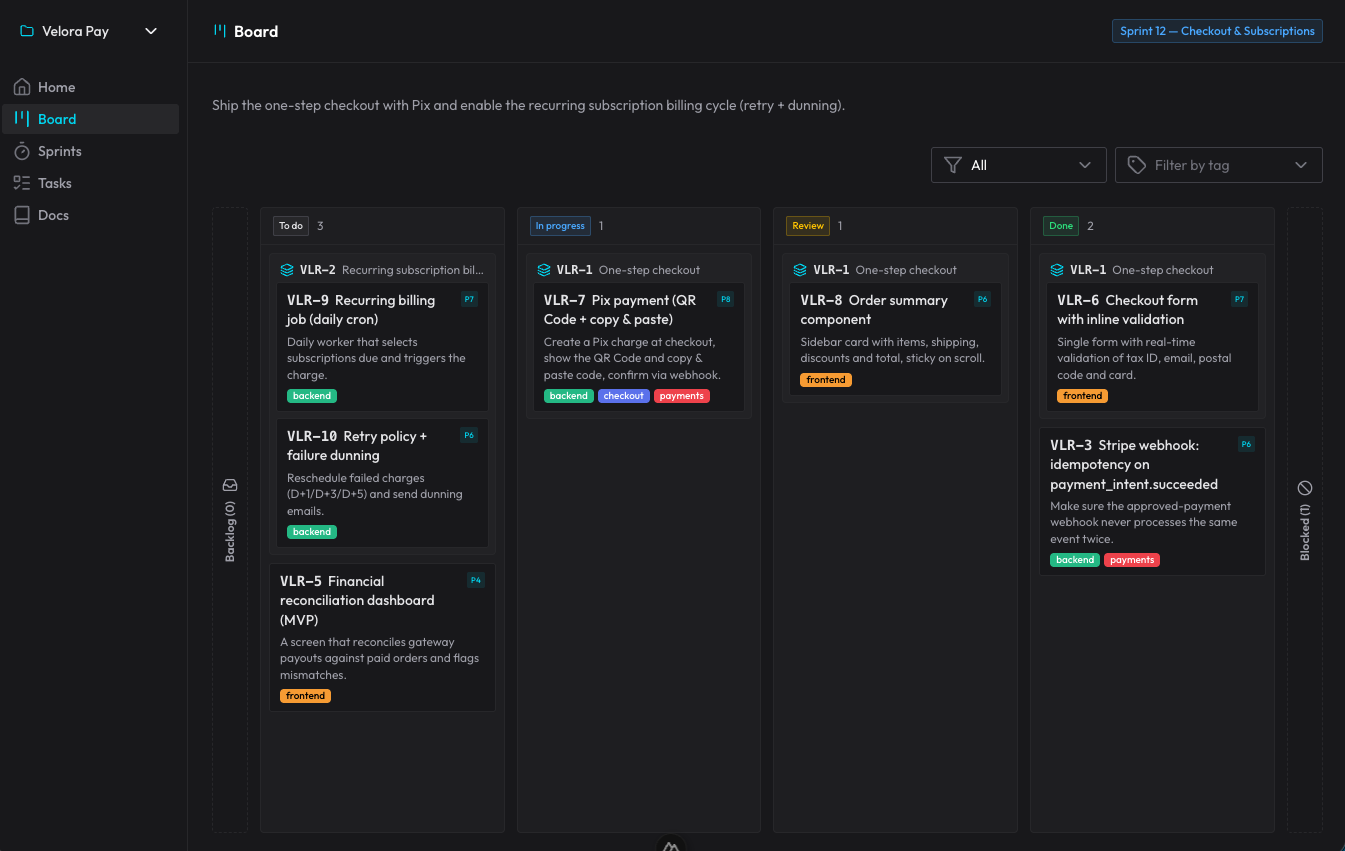
O fluxo inteiro acontece por skills + MCP. São cinco skills que disparam pelo que eu digo, sem eu chamar nenhuma na mão: uma pra orientar e operar a board, uma pra planejar uma demanda nova em sprint/histórias/tarefas, uma pra executar um card pelo seu ciclo de vida, uma de review (um gate obrigatório, rodado por um subagente limpo, que confere os critérios de aceite e caça bugs), e uma de autopilot pra avançar sozinha por vários cards prontos. A documentação durável — arquitetura, decisões (ADRs), padrões — vive nos docs do próprio organizer, que a IA lê antes de reinventar.
Como ele funciona na prática
A virada de chave, pra mim, foi esta: como o que foi planejado vive no organizer e não na sessão, eu posso executar cada tarefa numa sessão completamente limpa, sem perder qualidade. O agente abre, lê a board, entende onde está, faz o trabalho. Não importa se o contexto anterior já evaporou — o plano não estava na cabeça dele, estava no banco.
Isso resolve de uma vez os dois fantasmas: a ordem de execução (o que depende do quê está explícito nos blockers) e o delírio (ele parte do que foi decidido, não de uma lembrança vaga). E me deixa tocar várias frentes ao mesmo tempo, sequencial ou paralelo, sem me perder.
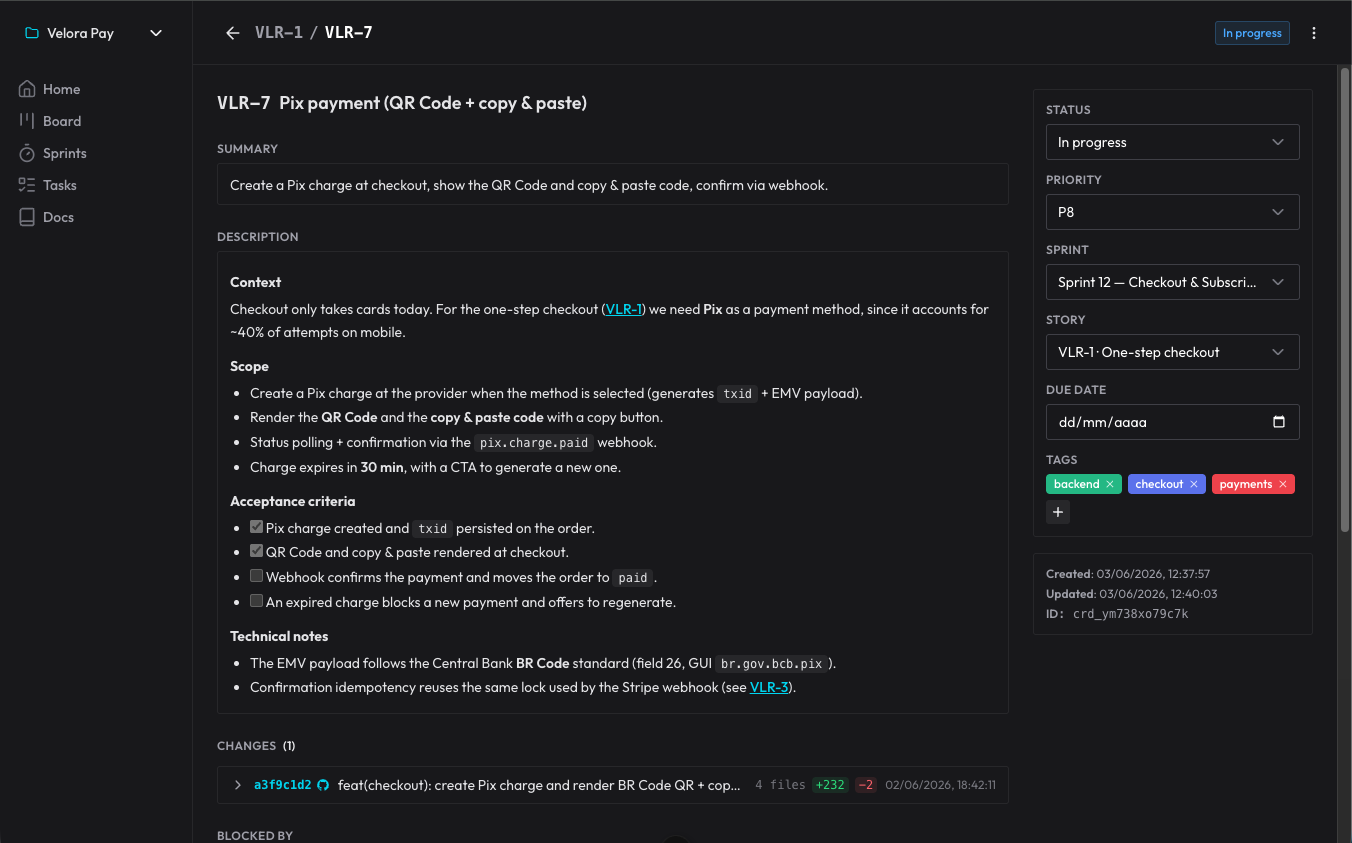
As decisões não se perdem porque viram comentários no card: o agente registra por que fez de um jeito, e eu respondo ali. Na sessão seguinte, ele lê os comentários que ainda não tinha visto e segue daquele ponto. É um registro de decisões que sobrevive ao fim de cada conversa.
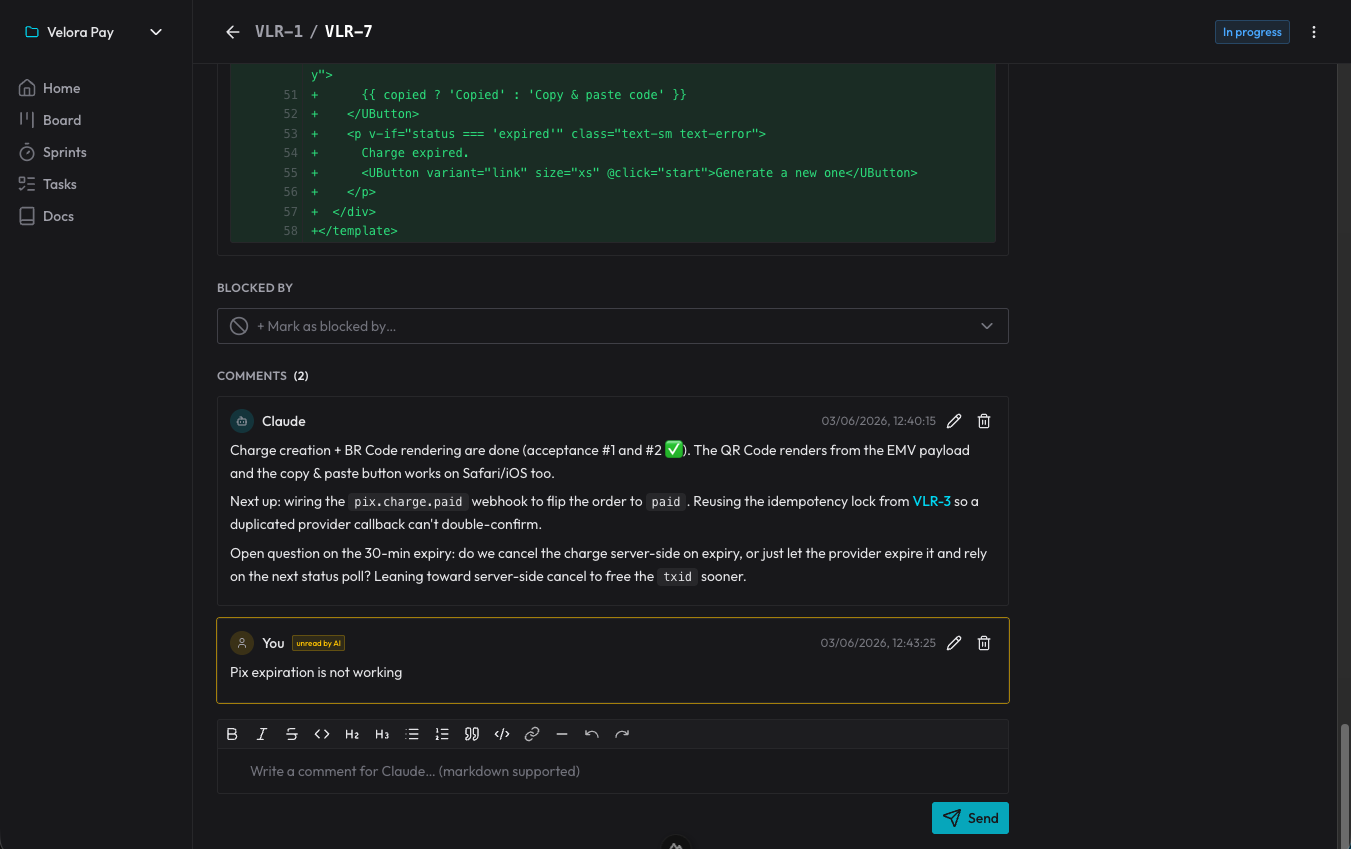
O efeito colateral mais gostoso: o repositório voltou a ser só o produto. Nada de pastas de spec engordando o git. O “o que fazer e por quê” mora no organizer, acessível de qualquer sessão; o código mora no repo. Cada coisa no seu lugar.
Como começar
Ele roda como plugin do Claude Code (as cinco skills + o servidor MCP), com a stack inteira em Docker. Pra subir:
1. Suba a stack (Postgres + migrations + API + UI + MCP, de uma vez):
git clone https://github.com/fmilioni/claude-organizer.git
cd claude-organizer
cp .env.example .env
docker compose up -d --buildA UI fica em http://localhost:4401, a API em :4400 e o MCP em :4402/mcp. As migrations rodam sozinhas antes da API subir.
2. Instale o plugin — ele entrega as skills e registra o MCP, sem precisar de claude mcp add:
/plugin marketplace add fmilioni/claude-organizer
/plugin install claude-organizer@claude-organizer3. Converse com o Claude. É só falar. “Quero planejar tal funcionalidade” dispara a skill de planejamento; “vamos continuar, o que é o próximo?” faz a IA ler a board e seguir de onde parou. As skills triggam pelo que você diz — você não precisa decorar comando nenhum.
O projeto é open source (MIT). Dá pra rodar 100% local com Docker ou hospedar numa VPS e apontar o Claude Code pra lá.
Quero saber como você organiza isso
Essa é, no fundo, a ponte que mais me interessa: trazer a disciplina de processo que a engenharia já tem pra dentro do jeito novo de construir, com IA no volante. O claude-organizer é a minha tentativa de fechar esse buraco — e ele nasceu de uma dor real, de ver bom trabalho se perder entre uma sessão e outra.
E você, como anda lidando com isso? Joga tudo num arquivo de spec? Confia na memória do modelo? Tem algum fluxo que funciona? Me conta nos comentários — quero muito ouvir como outras pessoas estão resolvendo esse mesmo problema.
E se quiser experimentar, o código está todo aberto: clone, teste e contribua no GitHub. Feedback e PR são muito bem-vindos.