ИИ изменил то, как я создаю софт
Уже довольно давно я не пишу большую часть кода руками. Я описываю, чего хочу, проверяю, корректирую курс, а ИИ исполняет. Это изменило всё: то, что раньше занимало целый день набора текста, теперь делается за минуты. Выпуск перестал быть вопросом того, сколько часов я могу просидеть в кресле, и стал вопросом того, насколько хорошо я умею управлять машиной.
Но любой прирост скорости обнажает новое узкое место. И моё появилось быстро.
Узкое место, которое заняло освободившееся место
У кодового агента нет памяти между сессиями. Когда я закрываю терминал и снова открываю его завтра, он понятия не имеет, о чём мы договорились вчера, почему мы так решили, что уже было готово, а чего не хватало. Каждая сессия начинается с нуля.
Пока работы было немного, я мог держать всё это в голове. Но как только ИИ начал выдавать результат по-настоящему быстро, я обнаружил, что у меня открыто сразу несколько фронтов — и самой сложной частью моего дня было уже не написание кода. Это было удержание в голове состояния дел. Что решено, что от чего зависит, что уже сделано, а что осталось наполовину.
Иными словами: документация перестала быть роскошью «на потом» и стала тем, на чём держится движение проекта. Без неё ИИ начинает галлюцинировать — переписывает то, что уже существовало, игнорирует решение, которое мы приняли на прошлой неделе, выполняет всё в неправильном порядке. Качество того, что он выдаёт, стало напрямую зависеть от того, насколько хорошо работа организована и зафиксирована.
Я перепробовал почти всё — и все упирались в одну и ту же стену
Я не стал сразу бросаться изобретать велосипед. Я месяцами пробовал плагины и навыки, которые сообщество создавало именно для решения этой проблемы: superpowers, GSD (get-shit-done), cavekit и другие.
У всех есть свои достоинства. Это хорошо продуманные проекты, полные хороших идей о том, как привнести процесс и дисциплину в работу агента. Я многому научился у каждого из них. Но в итоге все они упирались в одну и ту же фундаментальную проблему: способ хранить то, что ИИ «знает», был грудой файлов спецификаций в Markdown, закоммиченных в репозиторий.
И на практике это бьёт по двум направлениям:
- Засоряет git. Каждый план превращается в горсть
.md-файлов, которые попадают в репозиторий вместе с кодом. История заполняется шумом процесса, а репозиторий тащит на себе слой бумажной волокиты, который, по сути, не является продуктом. - Быстро устаревает. Спецификация — это снимок момента. На следующий день реальность уже изменилась, а файл всё ещё на месте и уверенно утверждает то, что больше не действует. Тогда ИИ читает старый план как истину, и галлюцинация только усиливается.
Я хотел противоположности статичному файлу: я хотел живое состояние, которое ИИ запрашивал бы и обновлял по мере продвижения работы, — а не очередной документ, который в одиночку стареет в углу репозитория.
А что, если бы доска принадлежала самому ИИ?
Вот тогда мне и пришла идея. Любая команда разработки уже решила проблему «что делать, зачем и в каком порядке» — это называется доской задач. Jira, Trello, Linear. Почему бы у ИИ не было своей?
Только с одной важной инверсией: этой доской пользовался бы в основном сам ИИ, через MCP (протокол, который позволяет агенту запрашивать и редактировать внешние инструменты). Агент читает активный спринт, берёт следующую карточку, фиксирует решения, прикрепляет коммит, закрывает задачу. А я — человек — захожу через интерфейс главным образом для того, чтобы следить и проверять: видеть, что делается, в реальном времени, перетаскивать карточки, оставить комментарий, который он прочтёт в следующей сессии.
Это не ИИ, пользующийся человеческим инструментом. Это инструмент, спроектированный для ИИ, с окном, через которое человек может заглянуть внутрь.
Вот так и родился claude-organizer
claude-organizer — это то, что вышло из этой идеи. Это не просто доска: это целая экосистема вокруг организации работы агента. В ней есть проекты, спринты, истории и подзадачи, блокеры, теги, приоритеты — и интерфейс на Nuxt, который отражает всё это в реальном времени, обновляясь через WebSocket, пока ИИ работает.
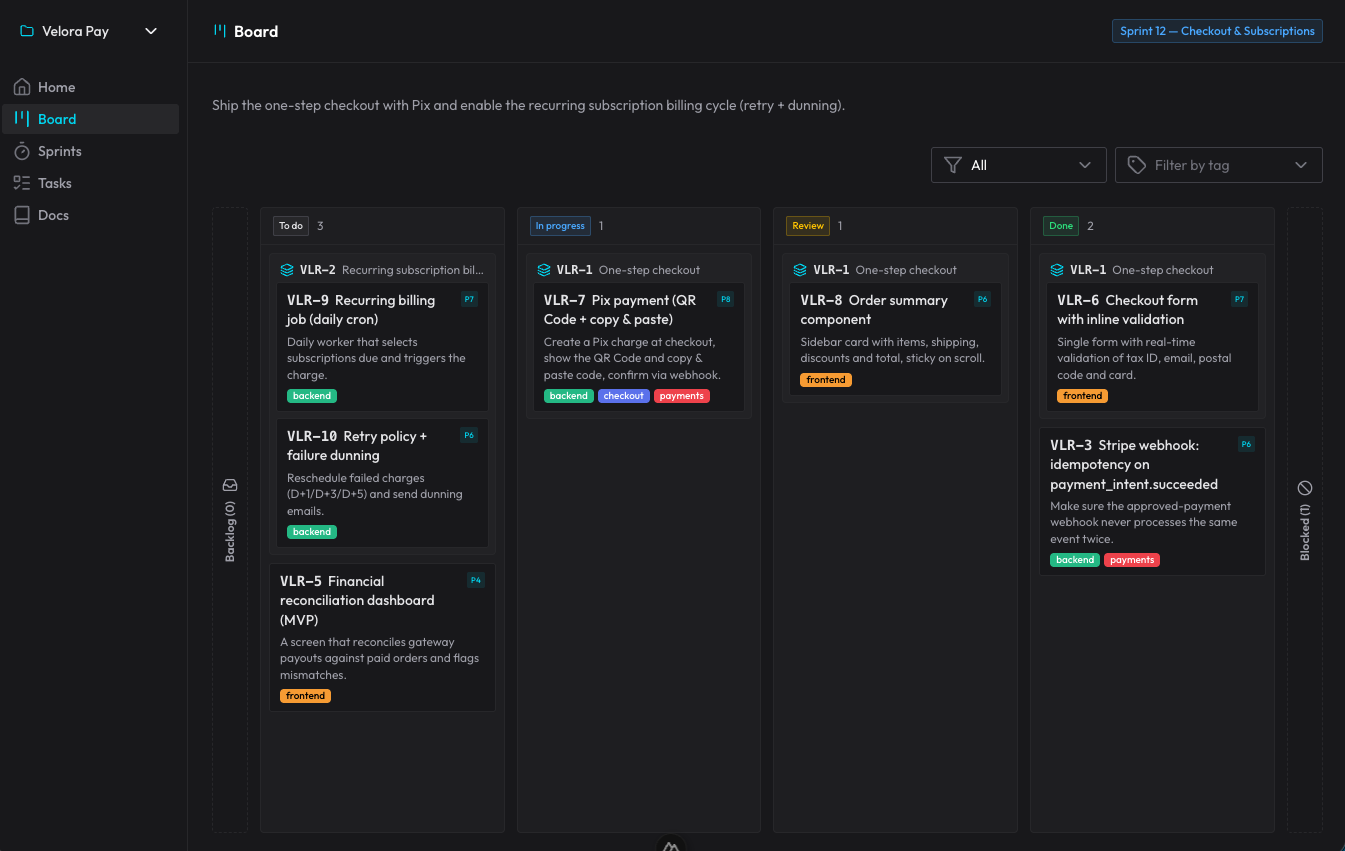
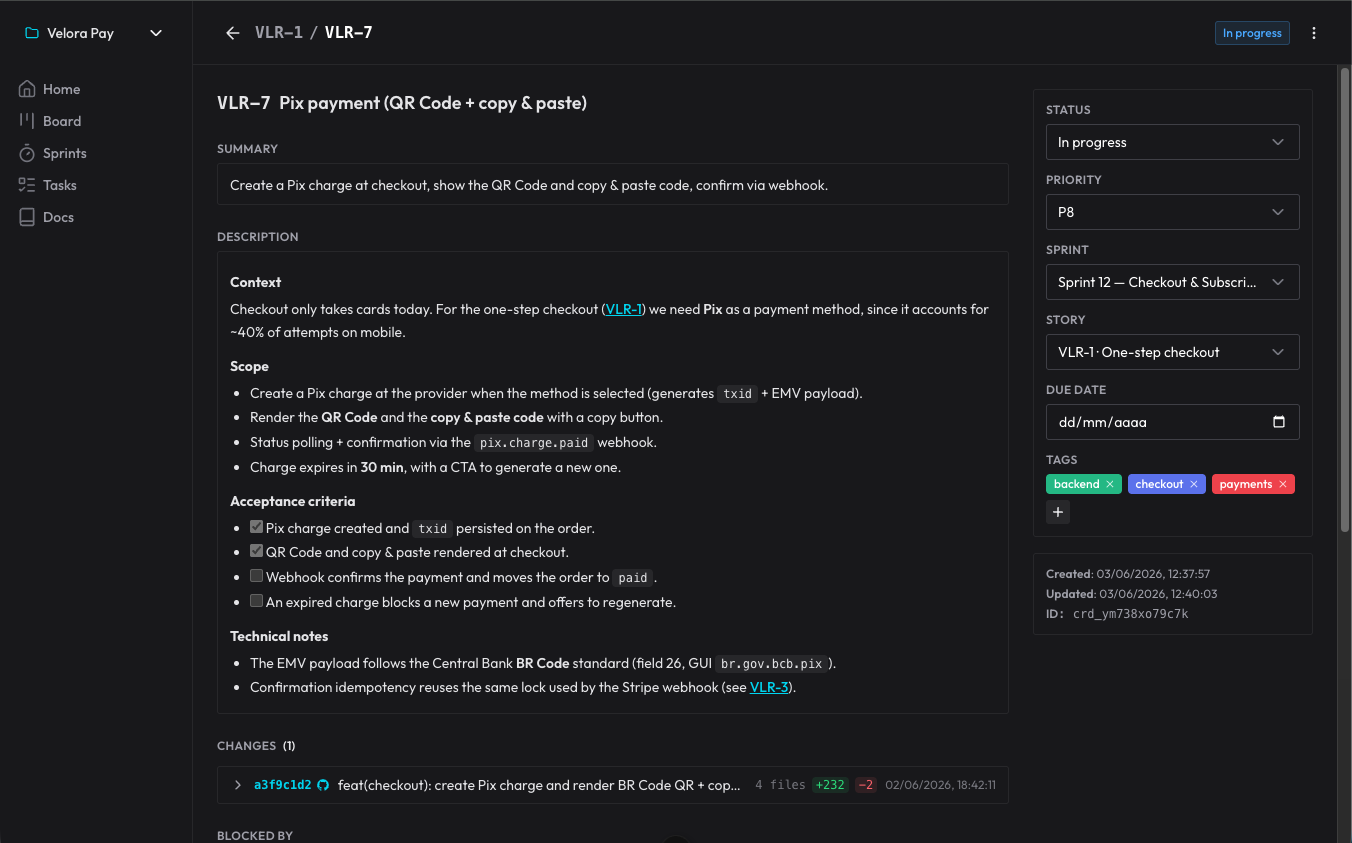
Весь процесс идёт через навыки + MCP. Есть пять навыков, которые срабатывают от того, что я говорю, без того, чтобы я вызывал хоть один из них вручную: один — чтобы ориентироваться и управлять доской, один — чтобы спланировать новую задачу в спринт/истории/задачи, один — чтобы выполнить карточку по её жизненному циклу, один для review (обязательный контроль, который выполняет чистый субагент, проверяющий критерии приёмки и охотящийся за багами) и один для autopilot — чтобы самостоятельно продвигаться по нескольким готовым карточкам. Долговечная документация — архитектура, решения (ADR), паттерны — живёт в docs самого organizer, которые ИИ читает, прежде чем изобретать заново.
Как это работает на практике
Переломный момент для меня был такой: поскольку запланированное живёт в organizer, а не в сессии, я могу выполнять каждую задачу в совершенно чистой сессии, не теряя качества. Агент открывается, читает доску, понимает, где он находится, делает работу. Неважно, что предыдущий контекст уже испарился, — план был не у него в голове, он был в базе данных.
Это разом решает обоих призраков: порядок выполнения (что от чего зависит, явно прописано в блокерах) и галлюцинации (он отталкивается от того, что было решено, а не от смутного воспоминания). И это позволяет мне вести сразу несколько фронтов, последовательно или параллельно, не теряясь.
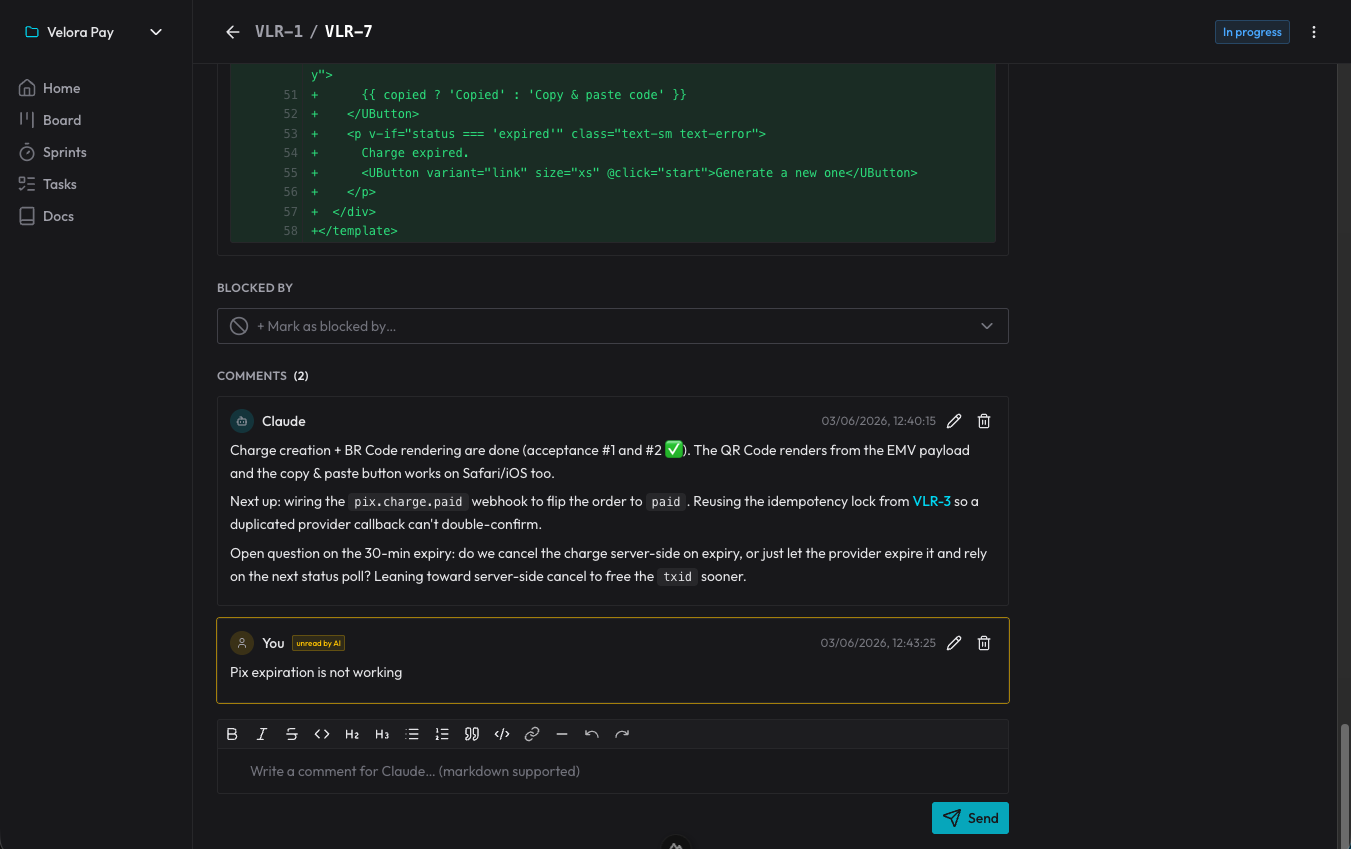
Решения не теряются, потому что превращаются в комментарии к карточке: агент фиксирует, почему сделал так, а я отвечаю прямо там. В следующей сессии он читает комментарии, которые ещё не видел, и продолжает с этого места. Это журнал решений, который переживает конец каждого разговора.
Самый приятный побочный эффект: репозиторий снова стал только продуктом. Никаких папок со спецификациями, раздувающих git. «Что делать и зачем» живёт в organizer, доступном из любой сессии; код живёт в репозитории. Каждому своё место.
С чего начать
Он работает как плагин для Claude Code (пять навыков + сервер MCP), со всем стеком в Docker. Чтобы запустить:
1. Поднимите стек (Postgres + миграции + API + UI + MCP, всё за один раз):
git clone https://github.com/fmilioni/claude-organizer.git
cd claude-organizer
cp .env.example .env
docker compose up -d --buildUI находится по адресу http://localhost:4401, API — на :4400, а MCP — на :4402/mcp. Миграции выполняются автоматически перед запуском API.
2. Установите плагин — он поставляет навыки и регистрирует MCP, без необходимости в claude mcp add:
/plugin marketplace add fmilioni/claude-organizer
/plugin install claude-organizer@claude-organizer3. Общайтесь с Claude. Просто скажите. «Хочу спланировать такую-то функцию» запускает навык планирования; «давай продолжим, что дальше?» заставляет ИИ прочитать доску и продолжить с того места, где он остановился. Навыки срабатывают от того, что вы говорите, — вам не нужно запоминать никаких команд.
Проект с открытым исходным кодом (MIT). Его можно запустить на 100% локально через Docker или разместить на VPS и направить Claude Code туда.
Хочу узнать, как это организуете вы
По сути, это тот самый мост, который интересует меня больше всего: привнести дисциплину процесса, которая уже есть в инженерии, внутрь нового способа создавать софт, где за рулём ИИ. claude-organizer — это моя попытка закрыть этот пробел, и он родился из реальной боли, из наблюдения за тем, как хорошая работа теряется между одной сессией и другой.
А как с этим справляетесь вы? Сваливаете всё в файл спецификации? Полагаетесь на память модели? Есть какой-то процесс, который работает? Расскажите мне в комментариях — мне очень хочется услышать, как другие люди решают эту же проблему.
А если захотите попробовать, код полностью открыт: клонируйте, тестируйте и вносите вклад на GitHub. Отзывы и PR очень приветствуются.