AIが、僕のソフトウェアの作り方を変えた
コードの大部分を手書きしなくなってからしばらく経ちます。僕は何が欲しいかを伝え、それをレビューし、方向を修正し、AIが実行する。これですべてが変わりました。以前はタイピングに午後いっぱいかかっていたことが、今では数分で終わる。リリースは、自分が何時間椅子に座っていられるかの問題ではなくなり、いかにうまくマシンを操縦できるかの問題になったのです。
でも、スピードの向上はどれも新しいボトルネックを露わにします。そして僕のボトルネックは、すぐに姿を現しました。
その代わりに現れたボトルネック
コーディングエージェントには、セッションをまたいだ記憶がありません。ターミナルを閉じて翌日また開くと、エージェントは昨日僕らが何を決めたのか、なぜそう決めたのか、何がもう終わっていて何が残っていたのか、まったく分かっていない。どのセッションもゼロから始まります。
仕事が小さいうちは、それを全部頭の中に抱えておけました。でもAIが本当に速く成果物を出すようになると、僕は同時にいくつもの作業を抱えるようになり——一日のいちばん難しい部分は、もはやコードを書くことではなくなっていました。それは物事の状態を覚えておくことでした。何が決まっていて、何が何に依存していて、何がもう終わっていて、何が中途半端なまま残っているのか。
つまり、ドキュメントは「あとで」やればいい贅沢品ではなくなり、プロジェクトを前に進め続けるための土台になったのです。それがなければ、AIは幻覚を起こします——すでに存在するものを書き直し、先週決めた判断を無視し、間違った順番で実行する。AIが出す成果物の品質は、作業がどれだけうまく整理され記録されているかに、直接かかってくるようになりました。
ほとんど全部試した——そしてどれも同じ壁にぶつかった
僕はいきなり車輪の再発明に飛び込んだわけではありません。まさにこれを解決するためにコミュニティが作ってきたプラグインやスキルを、何ヶ月もかけて試しました。superpowers、GSD(get-shit-done)、cavekit などです。
どれも価値があります。よく練られたプロジェクトで、エージェントにプロセスと規律を与える方法についての良いアイデアであふれていました。それぞれから多くを学びました。でも結局、どれも同じ根本的な問題にぶつかっていたのです。AIが「知っていること」を保存する方法が、リポジトリにコミットされた Markdown の spec ファイルの山だったということです。
そして実際のところ、これは2つの形で痛みをもたらします。
- gitを汚す。 計画ひとつひとつが、コードと一緒にプッシュされる一握りの
.mdになる。履歴はプロセスのノイズで埋まり、リポジトリは、実のところ製品ではない書類の層を抱えることになる。 - すぐに古びる。 spec はある瞬間のスナップショットだ。翌日には現実はもう動いているのに、ファイルはそこに残り、もう通用しないことを自信たっぷりに主張し続ける。するとAIは古い計画を真実であるかのように読み、幻覚はさらにひどくなる。
僕が欲しかったのは、静的なファイルの正反対でした。作業が進むにつれてAIが参照し、更新していく生きた状態。リポジトリの片隅でひとりきり老いていくもう一つのドキュメントではありません。
もしそのボードがAI自身のものだったら?
そのとき、アイデアがひらめきました。どんなソフトウェアチームも「何を、なぜ、どんな順番でやるか」という問題はとっくに解決済みです——それはタスクボードと呼ばれています。Jira、Trello、Linear。なら、AIだって自分のボードを持っていていいはずでは?
ただし、ひとつ大事な逆転があります。このボードは主にAI自身によって、MCP(エージェントが外部ツールを参照・編集できるようにするプロトコル)経由で使われる。エージェントはアクティブなスプリントを読み、次のカードを取り、判断を記録し、コミットを添付し、タスクを閉じる。そして僕——人間——は、主に進捗を追い、レビューするためにインターフェースから入る。何が行われているかをリアルタイムで見て、カードをドラッグし、次のセッションでAIが読むコメントを残す。
これはAIが人間のツールを使っているのではありません。AIのために設計されたツールに、人間が中をのぞくための窓がついている、ということです。
こうして claude-organizer が生まれた
claude-organizer は、そのアイデアから生まれたものです。単なるボードではありません。エージェントの作業を整理することをめぐるエコシステムです。プロジェクト、スプリント、ストーリーとサブタスク、ブロッカー、タグ、優先度があり——そしてそれらすべてをリアルタイムに映し出す Nuxt 製のインターフェースがあって、AIが作業している間 WebSocket で更新されます。
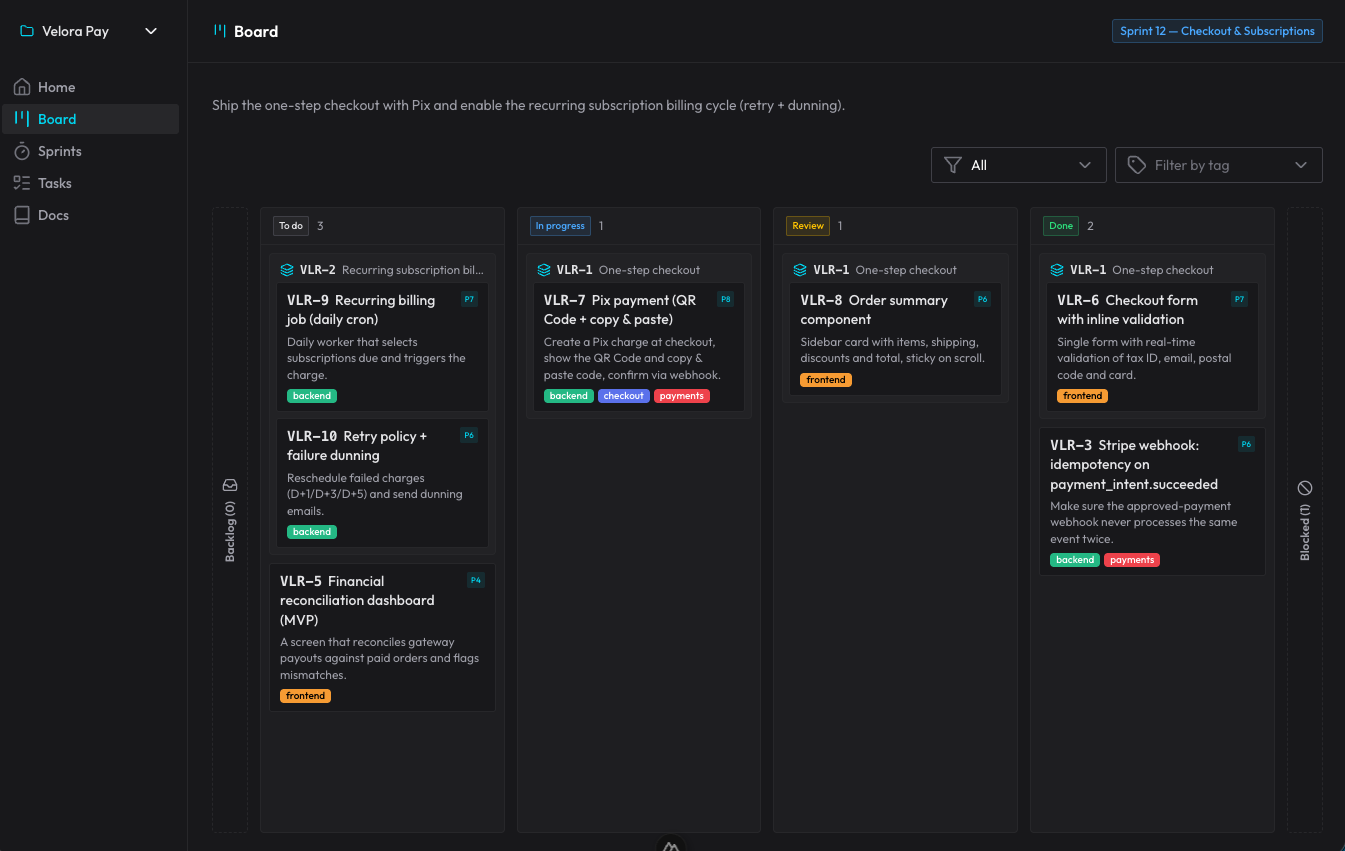
フロー全体はスキル + MCPで動きます。僕が言ったことに反応して発火する5つのスキルがあり、自分で手動で呼び出すことはありません。ひとつはボードを案内し操作するため、ひとつは新しい要望をスプリント/ストーリー/タスクに計画するため、ひとつはカードをそのライフサイクルに沿って実行するため、ひとつはレビュー用(クリーンなサブエージェントが実行する必須のゲートで、受け入れ基準を確認しバグを狩る)、そしてひとつは複数の準備済みカードを自分で進めていくautopilot 用です。長く残るドキュメント——アーキテクチャ、判断(ADR)、パターン——は、organizer 自身のdocsに置かれ、AIは何かを再発明する前にそれを読みます。
実際のところ、どう動くのか
僕にとっての本当の転換点はこれでした。計画されたものがセッションではなくorganizer の中に生きているので、僕は各タスクをまったくクリーンなセッションで、品質を落とすことなく実行できる。エージェントは開いて、ボードを読み、自分がどこにいるかを理解し、作業をする。それまでのコンテキストがもう蒸発していても関係ありません——計画はエージェントの頭の中ではなく、データベースの中にあったのですから。
これで2つの亡霊が一度に片づきます。実行の順序(何が何に依存するかはブロッカーに明示されている)と、幻覚(曖昧な記憶からではなく、決まったことから出発する)です。そして、僕は同時に複数の作業を、順番にでも並行してでも、迷子になることなく進められるようになります。
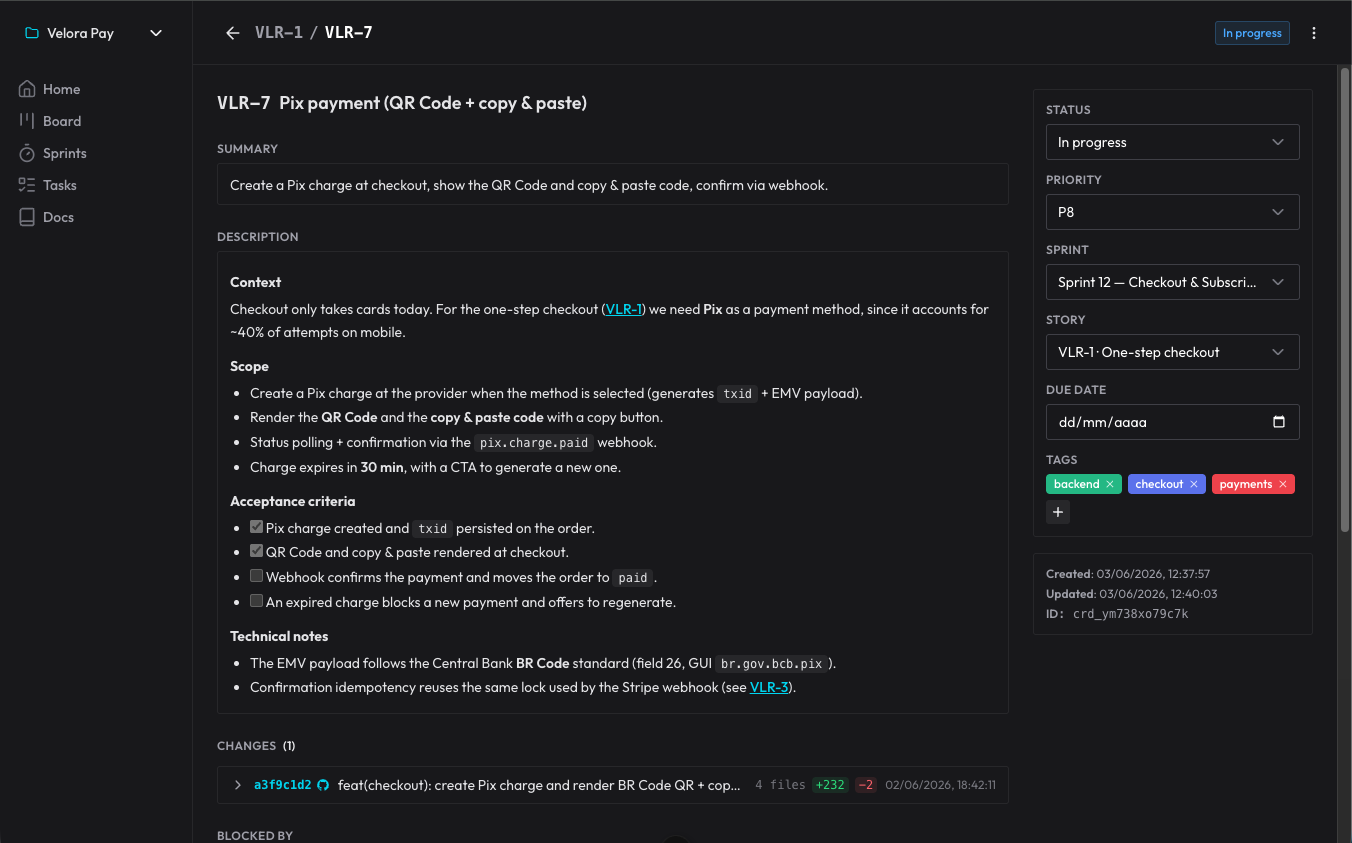
判断が失われないのは、それらがカードのコメントになるからです。エージェントはなぜある方法でやったのかを記録し、僕はそこに返信する。次のセッションで、エージェントはまだ見ていなかったコメントを読み、その地点から続ける。会話が終わっても生き残る判断のログです。
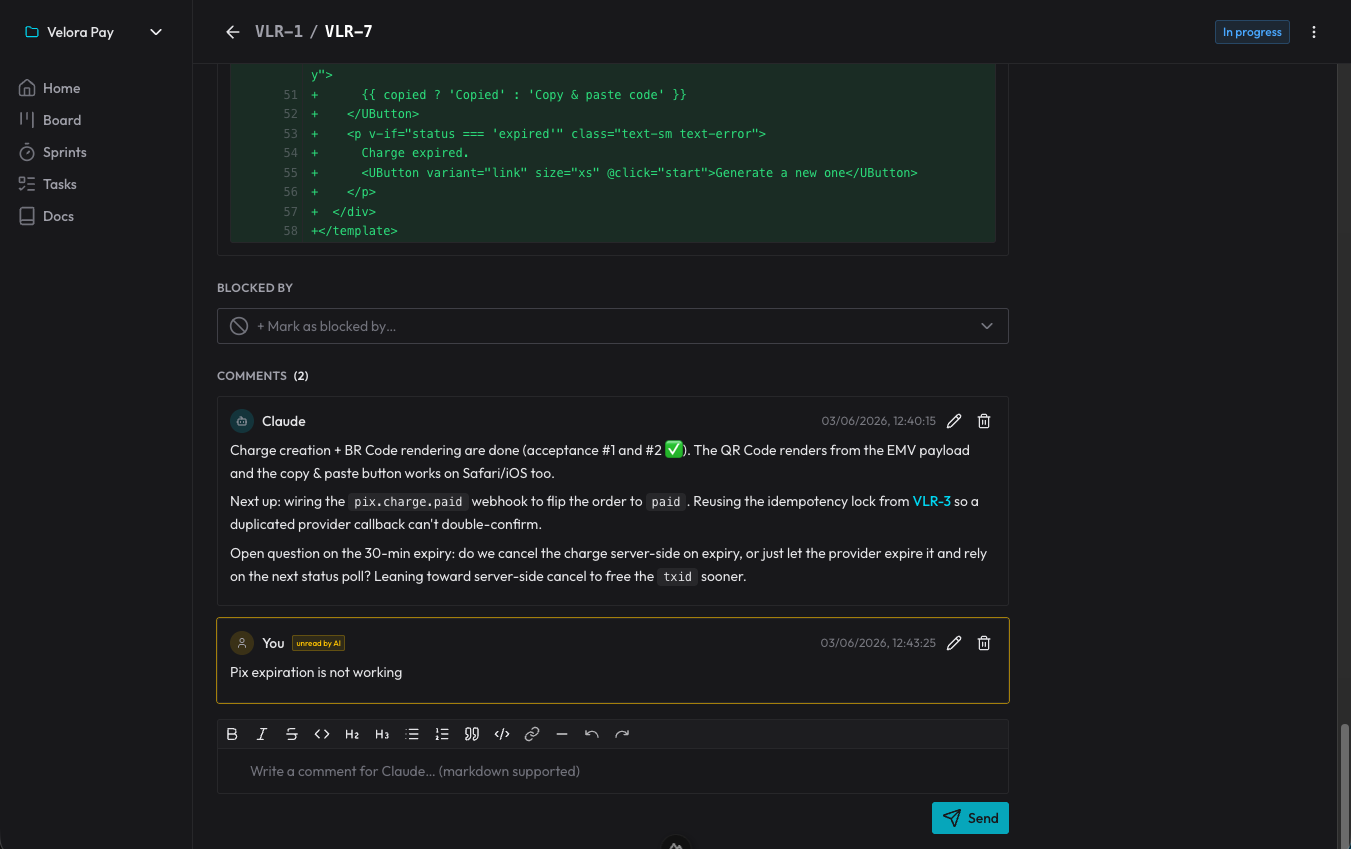
いちばん気持ちのいい副作用はこれです。リポジトリがまた製品だけのものに戻った。 gitを太らせる spec フォルダはもうない。「何を、なぜやるか」は organizer に住み、どのセッションからでも届く。コードはリポジトリに住む。それぞれが、それぞれの場所に。
はじめ方
これはClaude Code のプラグインとして動きます(5つのスキル + MCPサーバー)。スタック全体は Docker の中です。立ち上げるには:
1. スタックを立ち上げる(Postgres + マイグレーション + API + UI + MCP を一度に):
git clone https://github.com/fmilioni/claude-organizer.git
cd claude-organizer
cp .env.example .env
docker compose up -d --buildUI は http://localhost:4401、API は :4400、MCP は :4402/mcp にあります。マイグレーションは API が立ち上がる前に自動で実行されます。
2. プラグインをインストールする — これがスキルを届け、かつ MCP を登録します。claude mcp add は不要です:
/plugin marketplace add fmilioni/claude-organizer
/plugin install claude-organizer@claude-organizer3. Claude と話す。 ただ口にするだけ。「こういう機能を計画したい」と言えば計画スキルが発火し、「続けよう、次は何?」と言えばAIがボードを読んで前回の続きから進めます。スキルはあなたの言ったことから発火する——コマンドを覚える必要はありません。
このプロジェクトはオープンソース(MIT)です。Docker で100%ローカルに動かすことも、VPSにホストして Claude Code をそこに向けることもできます。
あなたがこれをどう整理しているか知りたい
これは突きつめると、僕がいちばん興味を持っている橋です——工学がすでに持っているプロセスの規律を、AIをハンドルに据えた新しい作り方の中に持ち込むこと。claude-organizer は、その穴を埋めようとする僕の試みであり——そして、良い仕事がセッションとセッションの間で失われていくのを見てきた、本物の痛みから生まれました。
あなたは、これとどう付き合っていますか? 全部 spec ファイルに放り込んでいますか? モデルの記憶に頼っていますか? うまく回っているフローはありますか? コメントで教えてください——他の人がこの同じ問題をどう解決しているのか、ぜひ聞きたいです。
そして、もし試してみたいなら、コードはすべて公開されています:GitHub でクローンして、試して、貢献してください。フィードバックや PR は大歓迎です。